PDF에서 텍스트 추출하기
PDF에서 텍스트를 추출하는 가장 빠른 방법은 모든 페이지를 대신 읽어 주는 도구에 파일을 업로드하는 것입니다. 송장일 수도, 계약서일 수도, 은행 명세서나 스캔한 양식일 수도 있습니다. 복사해서 붙여넣으면 아예 안 되거나 레이아웃이 엉망이 되고, 손으로 다시 입력하자니 시간도 오래 걸리고 실수도 잦습니다.
이 가이드에서는 사람들이 왜 PDF에서 텍스트를 꺼내는지, 어떤 상황에서 특히 중요한지, 그리고 받은편지함에 있는 PDF를 바로 보내는 방법을 포함해 가장 쉽게 직접 해내는 방법을 설명합니다. 텍스트를 꺼내는 것은 PDF에서 데이터를 추출하는 여러 방법 중 하나입니다.
PDF에서 텍스트를 추출하는 이유
PDF는 공유하고 인쇄하기 위해 만들어진 형식이지, 안에 담긴 내용을 다시 활용하기 위한 형식이 아닙니다. 화면에서는 텍스트를 선택할 수 있어 보이지만, 막상 스프레드시트나 다른 시스템으로 옮기려고 하면 무너지고 맙니다. 줄이 서로 붙고, 열이 망가지며, 스캔한 페이지에서는 아무것도 얻지 못합니다.
사람들이 PDF에서 텍스트를 추출하는 흔한 이유는 다음과 같습니다.
- 회계 소프트웨어나 경비 보고서에 넣어야 하는 송장과 영수증
- 예산 관리와 장부 정리를 위한 은행 및 신용카드 명세서
- 핵심 조항을 검색 가능한 형식으로 정리해야 하는 계약서와 약정서
- 재고 시스템에 등록해야 하는 공급업체 가격표
- 주문 확인서와 배송 보고서
- 컨퍼런스 PDF에서 가져온 연락처 목록과 참가자 명단
- 발행된 보고서에서 옮겨야 하는 연구 데이터
- 매달 PDF로 도착하는 양식, 경비 보고서, 급여 명세서
필요한 텍스트는 이미 페이지 위에 있습니다. 어려운 건 그것을 실제로 쓸 수 있는 구조로, 깔끔하게 꺼내는 일입니다.
NiceData로 PDF에서 텍스트를 추출하는 방법
세 단계면 됩니다. 그리고 첫 단계에서는 시작하는 방법이 두 가지 있습니다.
1단계: PDF를 NiceData에 넣기
NiceData에 PDF를 전달하는 방법은 두 가지입니다. 평소 일하는 방식에 맞는 쪽을 고르세요.
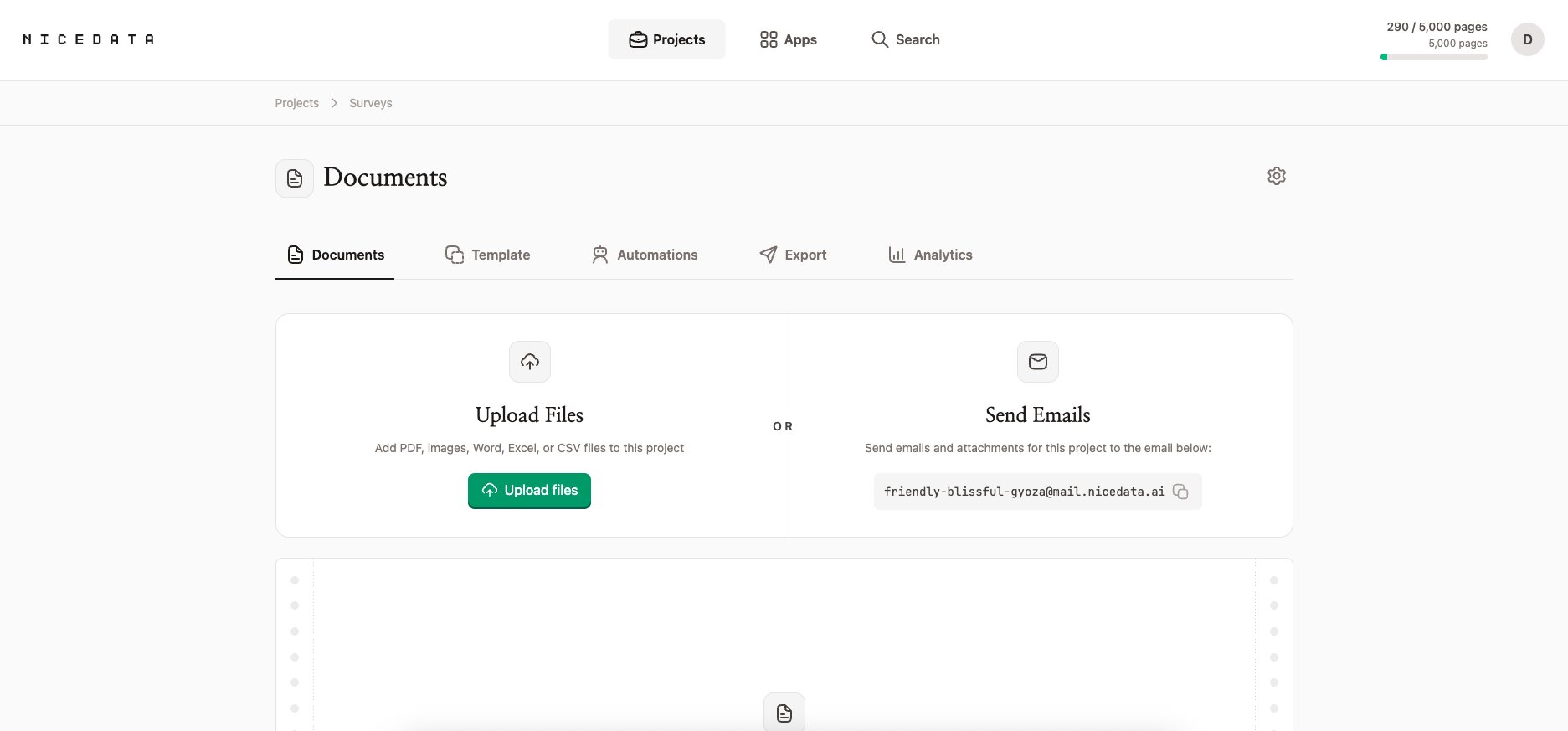
앱에서 업로드하기. NiceData에 로그인한 뒤 PDF를 업로드 영역으로 끌어다 놓거나, 파일 업로드를 클릭해 컴퓨터에서 고르세요. 파일 하나만 올려도 되고 여러 개를 한 번에 올려도 됩니다. 한 페이지짜리 PDF든 여러 페이지짜리 PDF든 모두 처리되며, 스캔한 PDF와 페이지를 찍은 사진도 마찬가지입니다. 미리 정리할 필요도 없습니다. 비뚤어진 스캔본, 로고, 머리글, 바닥글 모두 문제없습니다.
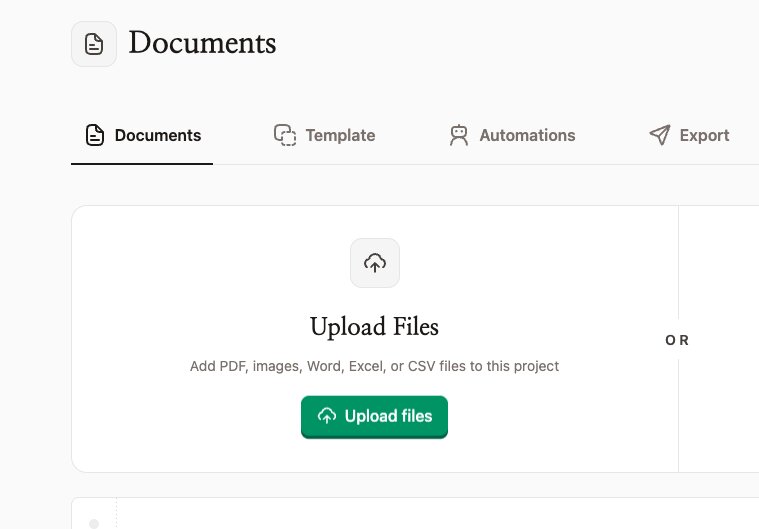
이메일 첨부로 보내기. NiceData의 모든 프로젝트에는 고유한 이메일 주소가 있으며, 프로젝트 설정에서 복사할 수 있습니다. PDF를 이메일에 첨부해 그 주소로 보내거나, 문서가 자동으로 도착하도록 자동 전달을 설정하세요. NiceData는 첨부 파일이 도착하는 순간, 직접 업로드한 파일과 똑같은 방식으로 처리합니다. 이메일 한 통에 최대 10개의 파일을 첨부할 수 있으며, NiceData가 첨부 파일을 읽을지, 이메일 본문을 읽을지, 둘 다 읽을지 선택할 수 있습니다.
2단계: NiceData가 텍스트를 읽도록 두기
PDF가 도착하는 즉시 NiceData가 읽기 시작합니다. AI를 활용해 페이지의 모든 텍스트 줄과 모든 열, 머리글, 날짜, 금액을 인식하고, 이 모두를 깔끔하게 정리된 항목으로 정돈합니다.
문서에 표시를 하거나 무엇이 어디에 있는지 알려 줄 필요가 없습니다. 처음 보는 문서에서도 NiceData가 알아서 파악합니다. 대부분의 PDF는 1분 안에 처리가 끝납니다.
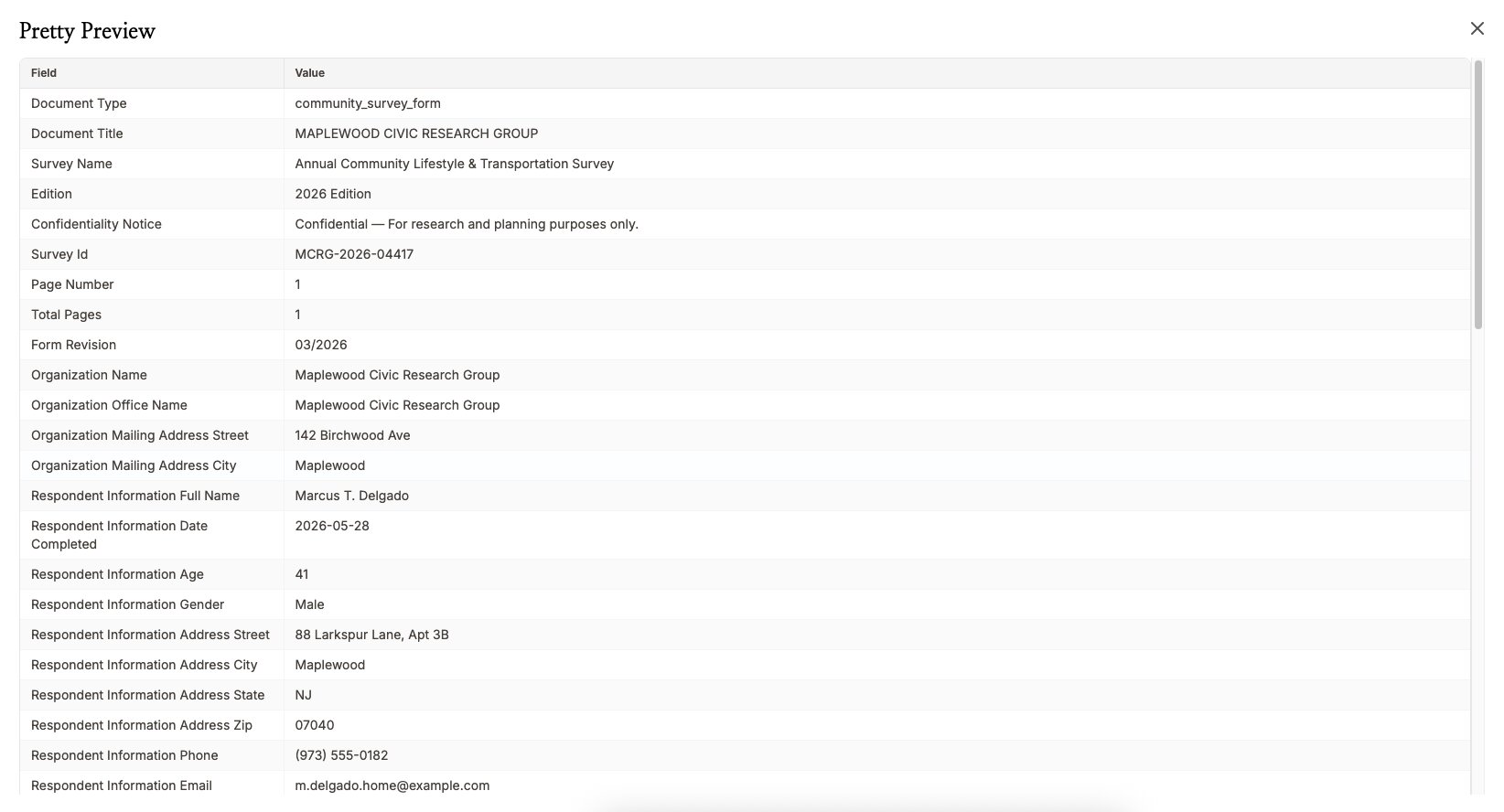
3단계: 데이터 내보내기
추출이 끝나면 오른쪽 위의 다운로드 버튼을 클릭해 원하는 형식을 고르세요. NiceData는 텍스트를 깔끔한 파일로 제공하므로, 스프레드시트에서 바로 열거나 다른 도구로 넘길 수 있습니다.
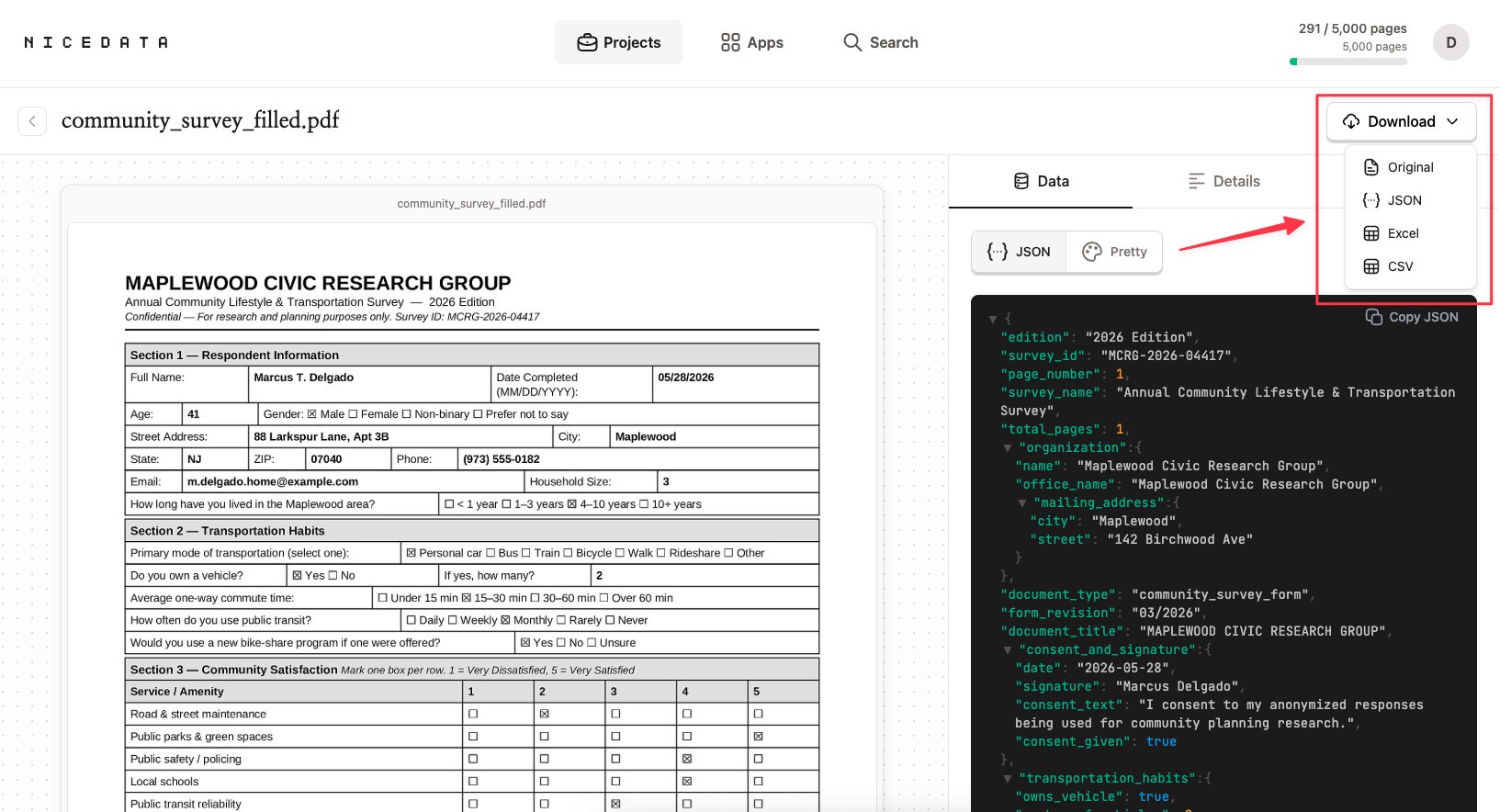
이게 전부입니다. 받은편지함이나 바탕화면에 있는 PDF에서 깔끔하게 쓸 수 있는 텍스트까지, 세 단계면 됩니다.
무엇을 추출할지 조절하는 방법
기본적으로 NiceData는 PDF에서 찾을 수 있는 모든 텍스트를 꺼냅니다. 특정 항목만 원한다면, 일상적인 말로 알려 주면 됩니다.
문서 유형에 맞는 템플릿을 만들고, 원하는 내용을 일상적인 말로 적은 뒤(“줄 항목과 합계만 주세요”처럼), 테스트 플레이그라운드에서 템플릿 안의 샘플로 확인해 보세요. NiceData는 그때부터 해당 프로젝트에 업로드하거나 이메일로 보내는 모든 PDF에 그 템플릿을 적용합니다.
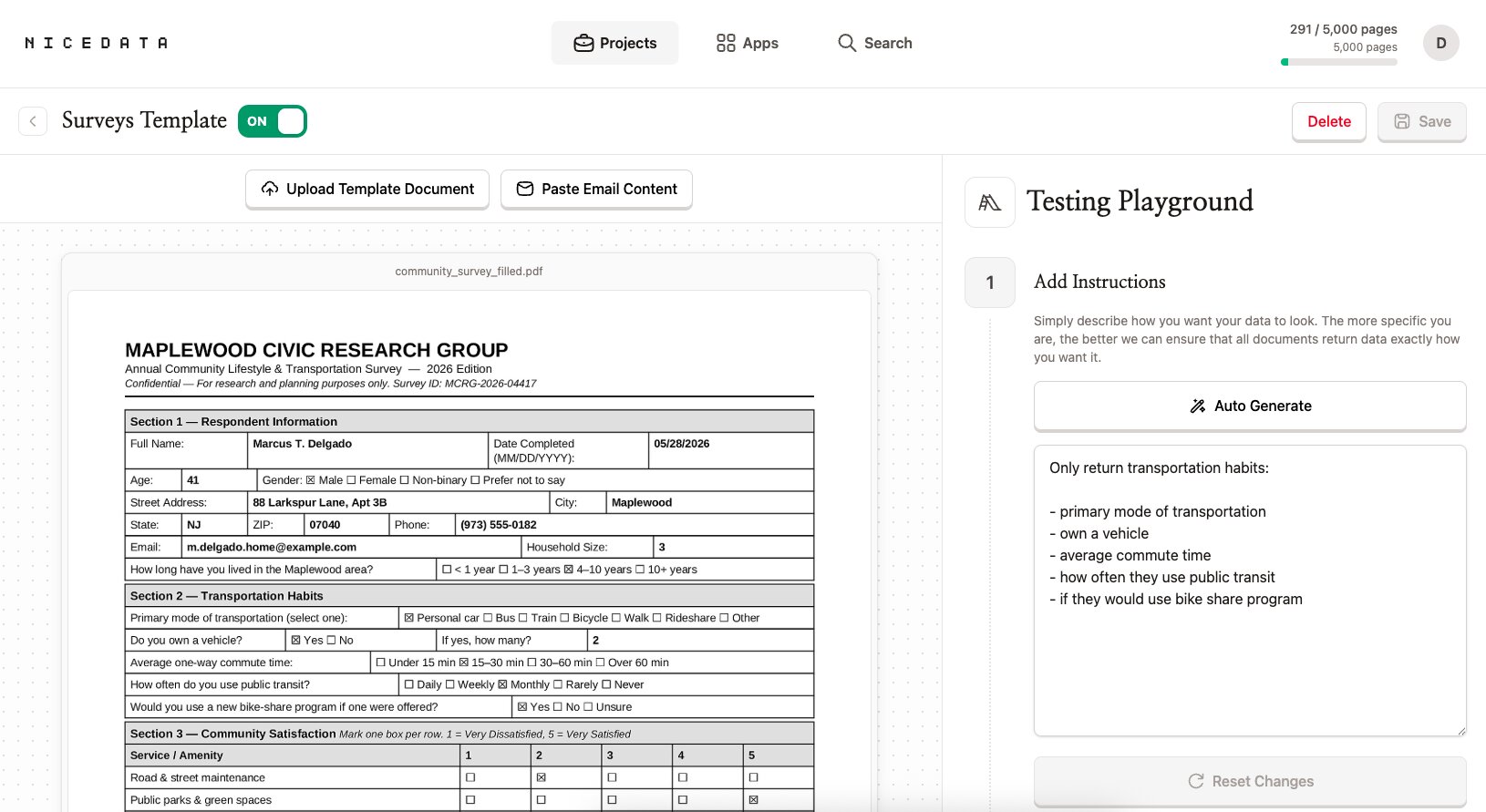
작성할 규칙도, 연결할 항목도, 정규식도 없습니다. 원하는 것을 설명하기만 하면 나머지는 NiceData가 알아서 합니다.
NiceData가 PDF에서 텍스트를 추출하는 가장 간단한 방법인 이유
PDF에서 텍스트를 추출해 준다고 약속하는 대부분의 도구는 사용자에게 많은 수고를 요구합니다. 문서 유형마다 시각적 템플릿을 직접 그리고, 각 항목을 페이지의 특정 영역에 연결해야 합니다. 라벨이 붙은 수십 개의 예시로 모델을 학습시켜야 합니다. 특정 항목을 찾도록 규칙을 작성해야 합니다. 어떤 도구는 문서 하나를 읽으려고 개발자 계정에 가입하고 코드를 연결하라고까지 합니다.
NiceData는 이 모든 과정을 건너뜁니다. PDF를 업로드하거나 이메일로 보내면 NiceData가 읽고, 결과를 다운로드하면 됩니다. 추출되는 내용을 더 세밀하게 다듬고 싶다면, 템플릿을 만들어 원하는 것을 일상적인 말로 설명하세요. 항목 연결도, 모델 학습도, 코드도 필요 없습니다.
바로 이것이 차이점입니다. 다른 도구들은 규모가 큰 기술팀을 위해 만들어졌습니다. NiceData는 PDF와 마감 기한을 가진 누구나를 위해 만들어졌습니다. 요금제 페이지에서 플랜을 고르거나, 무료 체험으로 시작해 직접 가진 문서로 사용해 보세요.
업로드할 수 있는 파일 형식
이 가이드의 주인공은 PDF이지만, NiceData는 거의 모든 종류의 문서를 읽습니다.
- PDF (한 페이지 또는 여러 페이지, 디지털 또는 스캔본)
- JPG와 JPEG (사진 및 스캔본)
- PNG (스크린샷 및 고화질 이미지)
- TIFF와 TIF (스캐너에서 자주 쓰는 형식)
- GIF와 WebP
- Word 문서 (DOC 및 DOCX)
- Excel 파일 (XLS 및 XLSX)
- CSV 및 일반 텍스트 파일
원한다면 모두 같은 프로젝트에 끌어다 놓거나 이메일로 보내세요. NiceData는 모두 똑같은 방식으로 처리합니다.
데이터를 내보내는 방법
NiceData가 PDF를 다 읽고 나면, 텍스트가 다음으로 향할 곳에 맞는 형식을 고르세요.
- CSV는 스프레드시트와 거의 모든 업무 도구에 알맞은 선택입니다. 항목 하나하나가 열이 되고, 문서 하나하나가 행이 됩니다.
- Excel은 동료와 파일을 공유할 때 가장 좋습니다. 머리글에 서식이 적용되고, 레이아웃이 깔끔하며, Microsoft Excel이나 Google Sheets에서 바로 열립니다.
- JSON은 개발자가 선호하는 형식입니다. 텍스트를 다른 도구나 연동, 맞춤형 앱으로 넘긴다면 JSON이 다루기 가장 쉽습니다.
- 대시보드에서 복사하기는 한 번만 처리하면 되는 작업에 가장 빠른 방법입니다. NiceData에서 문서를 열고, 필요한 항목을 복사해, 원하는 곳에 붙여넣으세요.
여러 형식을 섞어 쓸 수도 있습니다. 같은 PDF를 재무팀에는 CSV로, 개발자에게는 JSON으로 추가 작업 없이 내보낼 수 있습니다.
한 번에 한 문서씩 다운로드하는 것 외에도, Export 탭을 이용하면 프로젝트 전체의 데이터를 한꺼번에 꺼내는 여러 방법을 쓸 수 있습니다.
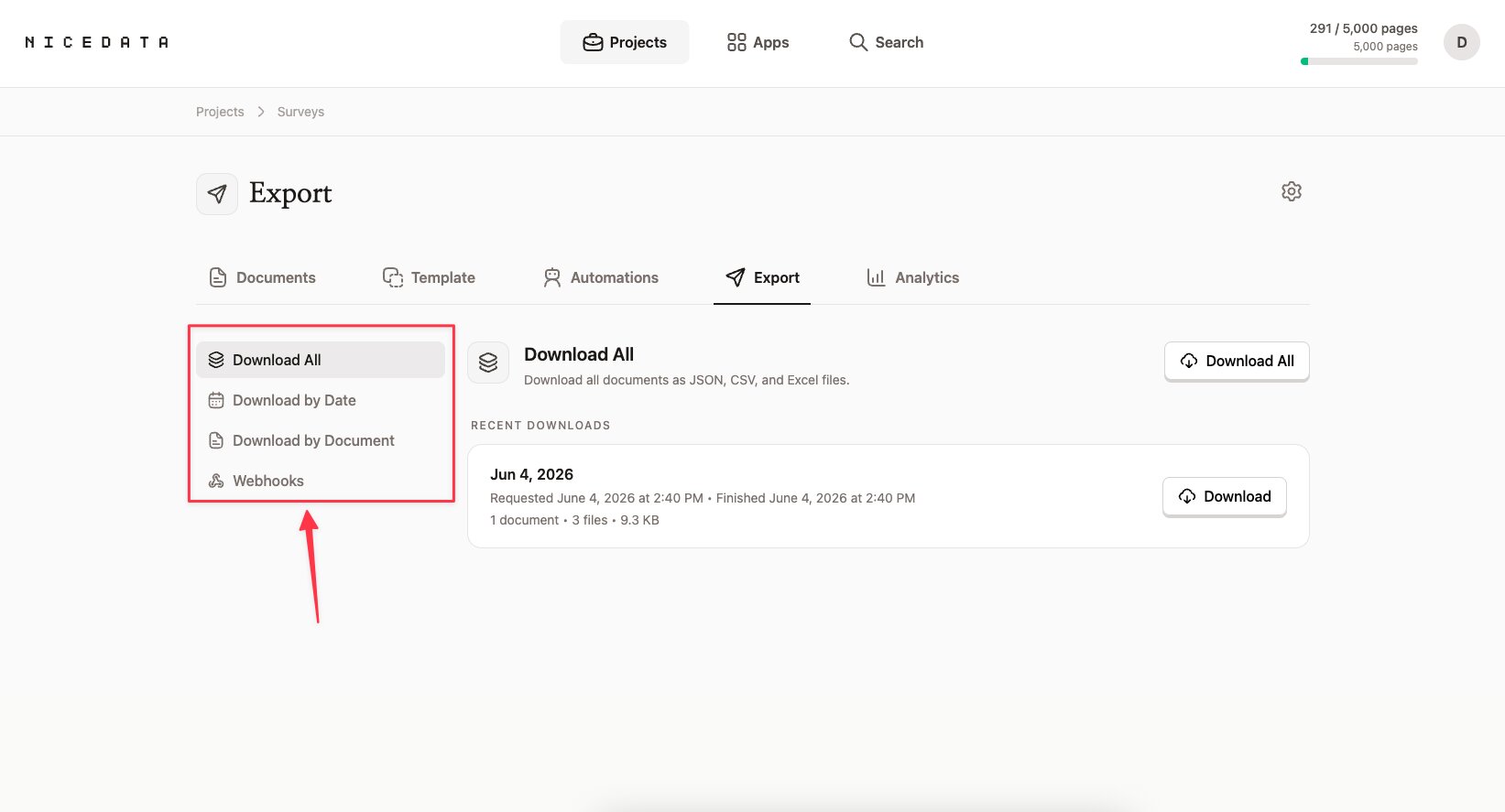
- Download All은 프로젝트의 모든 문서를 하나의 JSON, CSV, Excel 파일 묶음으로 만듭니다. 한 번의 클릭으로 전부 가져올 때 가장 좋습니다.
- Download by Date는 직접 고른 날짜 범위 안의 문서로만 내보내기를 한정하므로, 지난달이나 지난 분기 것만 꺼낼 수 있습니다.
- Download by Document는 원하는 특정 문서를 직접 골라 그것만 내보낼 수 있게 해 줍니다.
- Webhooks는 문서 처리가 끝나는 순간 추출한 데이터를 다른 도구로 보내 주므로, 손으로 직접 다운로드할 필요가 전혀 없습니다.
자주 묻는 질문
무료로 사용해 볼 수 있나요?
네. NiceData는 25페이지 추출을 포함한 14일 무료 체험을 제공합니다. 신용카드도 필요 없습니다. 구독 여부를 결정하기 전에 직접 가진 PDF로 텍스트를 추출해 볼 수 있습니다.
코딩을 할 줄 알아야 하나요?
아니요. NiceData는 코드 한 줄 써 본 적 없는 분들을 위해 만들어졌습니다. 모든 작업이 브라우저 안에서 이루어집니다. 파일을 폴더로 끌어다 놓거나 이메일을 보낼 수 있다면, NiceData로 PDF에서 텍스트를 추출할 수 있습니다.
추출 정확도는 어느 정도인가요?
저희 경험상 매우 정확합니다. NiceData는 최신 AI로 PDF를 읽기 때문에 디지털 파일, 스캔본은 물론 대부분의 손글씨 페이지까지 잘 처리합니다. 처음 보는 문서에서도 줄, 열, 머리글, 날짜, 합계를 정확하게 잡아냅니다.
여러 페이지로 된 PDF도 처리할 수 있나요?
네. 여러 페이지로 된 PDF를 업로드하면 NiceData가 문서당 최대 25페이지까지 모든 페이지를 읽습니다. 각 페이지는 월 요금제에서 1페이지로 계산되므로, 20페이지짜리 PDF는 사용량에서 20페이지를 차지합니다.
업로드 대신 PDF를 이메일로 보낼 수 있나요?
네. 모든 프로젝트에는 고유한 이메일 주소가 있습니다. PDF를 첨부한 이메일을 전달하거나 보내면, 직접 업로드한 파일과 똑같은 방식으로 NiceData가 첨부 파일을 자동으로 처리합니다. 이메일 한 통에 최대 10개의 파일을 첨부할 수 있습니다.
제 데이터는 안전한가요?
네. 문서는 전송 중에도, 저장 시에도 암호화되며, 본인과 팀원만 접근할 수 있는 격리된 프로젝트 폴더에 보관됩니다. 또한 문서를 1일, 14일, 30일, 60일, 90일 후 자동으로 삭제되도록 설정할 수도 있습니다.
관련 가이드
이미지에서 텍스트 추출하기
NiceData로 어떤 이미지에서든 몇 초 만에 텍스트를 추출하세요. 사진, 스크린샷, 스캔본을 업로드하고 데이터를 JSON, CSV, Excel로 내보낼 수 있습니다. 코드 필요 없음.
PDF에서 표 추출하기
어떤 PDF에서든 몇 초 만에 표를 추출하세요. NiceData가 모든 행과 열을 스프레드시트에 바로 넣을 수 있는 깔끔한 격자로 다시 만들어 줍니다. 무료로 사용해보세요.
텍스트에서 키워드 추출하기
NiceData로 어떤 텍스트나 문서에서든 몇 초 만에 키워드를 추출하세요. 파일을 업로드하고 핵심 용어를 뽑아 CSV, Excel, JSON으로 내보낼 수 있습니다. 무료로 시작하세요.

Dace Willmott
Founder
NiceData aims to eliminate manual data entry from document workflows. We write about AI-powered document processing, data extraction best practices, and the tools that help teams move faster with cleaner data.