テキストからキーワードを抽出する
テキストからのキーワード抽出は、もう蛍光ペン片手にレポートやアンケートの回答、契約書を何ページも読み込む作業ではありません。ソフトウェアに書類を読ませれば、重要な用語を取り出せます。ファイルをアップロードして欲しいキーワードを説明するだけで、数秒で整ったリストが返ってきます。
このガイドでは、なぜチームはテキストからキーワードを抽出するのか、3 ステップで自分で行う方法、そして返ってくる用語を思いどおりに制御する方法を順に紹介します。
なぜテキストからキーワードを抽出するのか
キーワードとは、書類の意味を担う用語のことです。トピック、商品名、人名、繰り返し出てくる苦情、契約書の定義語などが該当します。長い文章からそれらを手作業で拾い出すのは時間がかかり、気づけば午後がまるごと消えているような仕事です。チームが自動化するよくある理由:
- コンテンツ・SEO チームは、記事や下書きから繰り返し登場するトピックやフレーズを取り出して、そのページが実際に何について書かれているかを把握します。
- 研究者は、インタビューの書き起こし、論文、レポートをテーマ別にタグ付けして、あとでグループ化や比較ができるようにします。
- サポートチームは、何百件ものチケットやフィードバックフォームから、商品名や繰り返し発生している問題を見つけ出します。
- マーケターは、レビューやアンケートの回答から、お客様が商品を表現するときに使う生の言葉を掘り出します。
- 法務・業務チームは、契約書から定義語、当事者名、期限を取り出します。
- 採用担当者は、山積みの履歴書からスキルと資格を抽出します。
どのケースでも目的は同じです。文字の壁を、並べ替えて、数えて、行動につなげられる短い構造化されたリストに変えることです。
NiceData でテキストからキーワードを抽出する方法
手順は 3 つです。それで全部です。
ステップ 1:書類をアップロードする
NiceData にサインインして、ファイルをアップロードエリアにドラッグします。1 ファイルでも数百ファイルでも一度に投げ込めますし、メールに添付してプロジェクトに直接送ることもできます。PDF、Word 文書、写真、スクリーンショット、スキャンのすべてに対応しています。
事前にテキストをきれいに整える必要はありません。撮影したアンケート用紙でも、清書されたレポートと同じように処理できます。
ステップ 2:NiceData にキーワードを抽出させる
アップロードが終わると、NiceData がすぐに読み始めます。AI が書類全体の内容を理解するので、単に出現回数の多い単語ではなく、意味を担っているトピック、名前、用語を拾い出せます。
マーカーを引く必要も、ページに印を付ける必要も、どこを見るか指定する必要もありません。すべての用語にラベルが付いた、そのまま使えるフィールドとして返ってきます。
ほとんどの書類は 1 分以内に処理が終わります。
ステップ 3:キーワードを書き出す
抽出が終わったら、いくつかの選択肢があります:
- NiceData のダッシュボードでキーワードを確認し、必要な部分をコピーする。
- CSV でダウンロードして、Excel、Google スプレッドシート、Numbers で開く。
- Excel でダウンロードして、見出しが整った状態でそのまま共有する。
- JSON でダウンロードして、開発者や別のツールに渡す。
これで終わりです。書類のフォルダから整ったキーワードのリストまで、3 ステップで完了です。
抽出されるキーワードを制御する方法
NiceData は標準で、書類の中で見つけられるすべての情報を読み取ります。キーワード抽出では、もっと絞り込んだ結果が欲しいことが多いはずです。その場合は、普通の日本語で指示できます。
書類の種類に合わせてテンプレートを作成し、欲しい内容を指示として書きます。例えば:
- 「この書類で最も重要なトピックを 10 個挙げて。」
- 「登場するすべての商品名を、それぞれの出現回数とあわせて取り出して。」
- 「この履歴書からスキルと資格を抽出して。」
- 「このフィードバックで繰り返し出てくる苦情を、テーマ別にまとめて一覧にして。」
そのあと、テンプレート内でサンプルの書類を使って試します。欲しいキーワードが返ってくるようになれば、それ以降そのプロジェクトにアップロードするすべての書類に、NiceData がその指示を適用します。
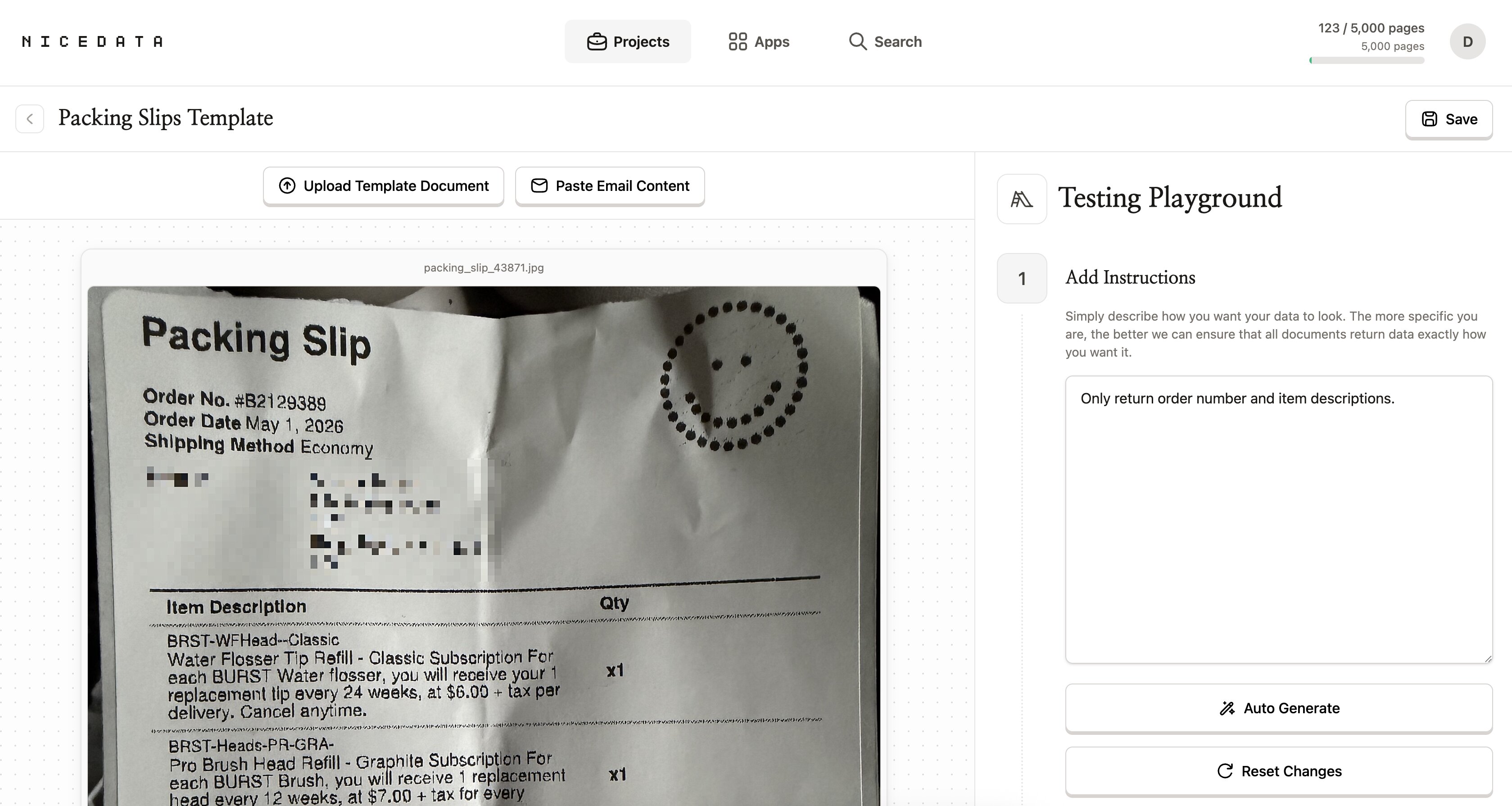
ルールを書く必要はありません。項目をマッピングする必要もありません。正規表現も不要です。欲しい結果を説明するだけで、あとは NiceData が処理します。
NiceData がテキストからキーワードを抽出する一番シンプルな方法である理由
キーワード抽出をうたう多くのツールは、ユーザーに作業を強いてきます。書類の種類ごとに視覚的なテンプレートを描き、各フィールドをページ上の領域にマッピングしないといけません。何十もの例で AI を学習させないと使い物になる結果が出ないこともあります。抽出ルールを書かないといけないこともあれば、レポート 1 本分析するためだけに開発者登録をしてコードをつなぎ込まないといけないこともあります。
NiceData はそれを全部スキップします。書類をアップロードして、NiceData が読んで、結果をダウンロードするだけです。返ってくるキーワードを調整したい場合は、テンプレートを作成して、欲しい内容を日本語の文章で記述するだけです(フィールドのマッピングなし、モデル学習不要、コード不要)。
ここが違いです。他のツールは大規模な技術チーム向けに作られています。NiceData は、書類と締切を抱えているすべての人のために作られています。14 日間無料で試して、その後は利用量に合ったプランを選べます。
アップロードできるファイル形式
NiceData は、よく使われる書類と画像の形式すべてからキーワードを抽出できます:
- PDF(1 ページでも複数ページでも)
- Word 文書(DOC と DOCX)
- JPG と JPEG(写真とスキャン)
- PNG(スクリーンショットや高画質画像)
- TIFF と TIF(スキャナーでよく使われる)
- Excel ファイルと CSV(テキストが表計算ファイルの中にある場合)
重要な用語だけでなく書類の文字をひとつ残らず取り出したい場合は、PDF からテキストを抽出する方法と画像からテキストを抽出する方法のガイドをご覧いただくか、まずは PDF からデータを抽出する方法で全体像をつかんでください。
抽出したキーワードの書き出し方
NiceData がテキストを読み終えたら、次にやりたいことに合わせて好きな形式でキーワードを書き出せます。
- CSV は、キーワードを表計算ソフトで並べ替えたり数えたりしたいときに最適です。各フィールドが列に、各書類が行になります。
- Excel は、結果を同僚と共有するのに向いています。見出しは整っていて、レイアウトもきれいで、Microsoft Excel や Google スプレッドシートでそのまま開けます。
- JSON は開発者がよく使う形式です。キーワードを別のツール、連携、自作アプリに渡すなら、JSON が一番扱いやすいです。
- ダッシュボードからコピーは、単発の作業に一番速い方法です。NiceData で書類を開いて、必要な用語をコピーして、好きな場所に貼り付けるだけです。
組み合わせもできます。同じプロジェクトをチーム用に Excel、開発者用に JSON で書き出せます。追加の手間はありません。
よくある質問
無料で試せますか?
はい。NiceData には 14 日間の無料トライアルがあり、25 ページ分の抽出が含まれます。クレジットカードは不要です。契約を決める前に、自分の書類で試せます。
コードが書けないとダメですか?
いいえ。NiceData は、コードを 1 行も書いたことがない人のために作られています。すべての作業はブラウザの中の、わかりやすい画面で完結します。ファイルをフォルダにドラッグできるなら、NiceData を使えます。
キーワード抽出の精度はどれくらいですか?
私たちの経験では、とても高いです。NiceData は最新の AI で書類を読んで内容を理解するので、単に単語の出現回数を数えるのではなく、本当に意味のある用語を拾い出します。印刷された書類、スキャン、写真、ほとんどの手書きメモまで、しっかり処理できます。
どの言語に対応していますか?
すべての言語です。NiceData は日本語、英語、フランス語、スペイン語、ドイツ語、イタリア語、ポルトガル語、韓国語、中国語、その他何十もの言語でテキストを読み取れます。書類の言語を指定する必要はありません。自動で判別します。
複数ページの PDF も扱えますか?
はい。複数ページの PDF をアップロードすると、NiceData は各ページを読みます。各ページは月間プランの 1 ページとしてカウントされるので、25 ページの書類は 25 ページぶんを消費します。
データは安全ですか?
はい。書類は通信中も保管中も暗号化され、あなたとチームだけがアクセスできる隔離されたプロジェクトフォルダに保存されます。1 日、14 日、30 日、60 日、90 日のいずれかで自動削除する設定もできます。
関連ガイド
PDFからテキストを抽出する
どんなPDFからも数秒でテキストを抽出。アップロードするかメールに添付して送るだけで、NiceDataがきれいに整理された構造化データに変換します。コードは一切不要です。
画像からテキストを抽出する
NiceData なら、どんな画像からも数秒でテキストを抽出できます。写真、スクリーンショット、スキャンをアップロードして、JSON、CSV、Excel でデータを書き出せます。コード不要。
PDFからデータを抽出する方法
NiceDataを使えば、あらゆるPDFから数秒でデータを抽出できます。テキスト、表、特定の項目を取り出し、CSV、Excel、JSONにエクスポート。設定もコードも不要。無料でお試しください。

Dace Willmott
Founder
NiceData aims to eliminate manual data entry from document workflows. We write about AI-powered document processing, data extraction best practices, and the tools that help teams move faster with cleaner data.