Comment extraire du texte d'une image
Si vous avez la photo d’un reçu, d’une facture, d’une carte de visite ou d’une capture d’écran remplie de texte, vous pouvez en extraire chaque mot en quelques secondes. Sans tout retaper à la main. Sans logiciel compliqué à configurer. Sans modèles à dessiner.
Ce guide vous montre comment extraire du texte d’une image avec NiceData, la façon la plus simple de transformer n’importe quel document en données propres et structurées, prêtes à être utilisées dans un tableur, une base de données ou ailleurs.
Pourquoi extraire du texte d’une image ?
La plupart des équipes passent des heures chaque semaine à retaper des informations qui existent déjà dans des images et des PDF. Quelques exemples courants :
- Reçus pour les notes de frais
- Factures des fournisseurs
- Cartes de visite collectées lors d’événements
- Notes manuscrites prises en réunion
- Captures d’écran d’e-mails ou de pages web
- Formulaires scannés remplis par les clients
- Photos de tableaux blancs après un brainstorming
Le faire à la main est lent et source d’erreurs. L’extraction automatique vous donne les mêmes données en quelques secondes, prêtes à être déposées dans un tableur ou envoyées à votre outil de comptabilité.
Comment extraire du texte d’une image avec NiceData
Il y a trois étapes. C’est tout le processus.
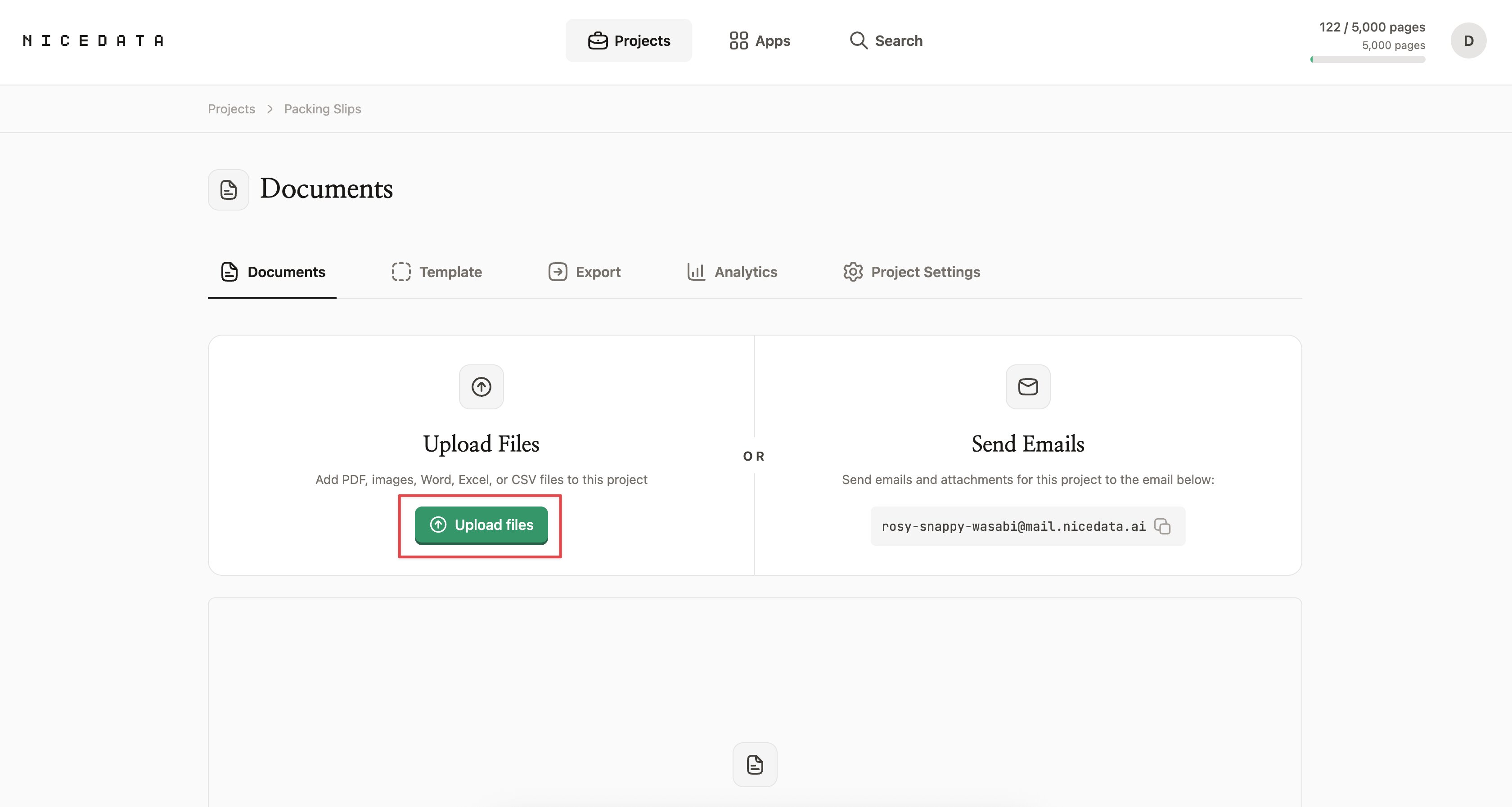
Étape 1 : Téléversez votre image
Connectez-vous à NiceData et glissez votre image dans la zone de téléversement. Vous pouvez déposer un fichier ou des centaines à la fois. NiceData accepte les images JPG, PNG, GIF, WebP et TIFF, ainsi que les PDF si votre scan est dans ce format.
Pas besoin de rogner, faire pivoter ou nettoyer l’image au préalable. Les photos prises avec votre téléphone fonctionnent. Les scans légèrement flous fonctionnent. Les pages avec du texte, des tableaux et des logos mélangés fonctionnent.
Étape 2 : Laissez NiceData lire l’image
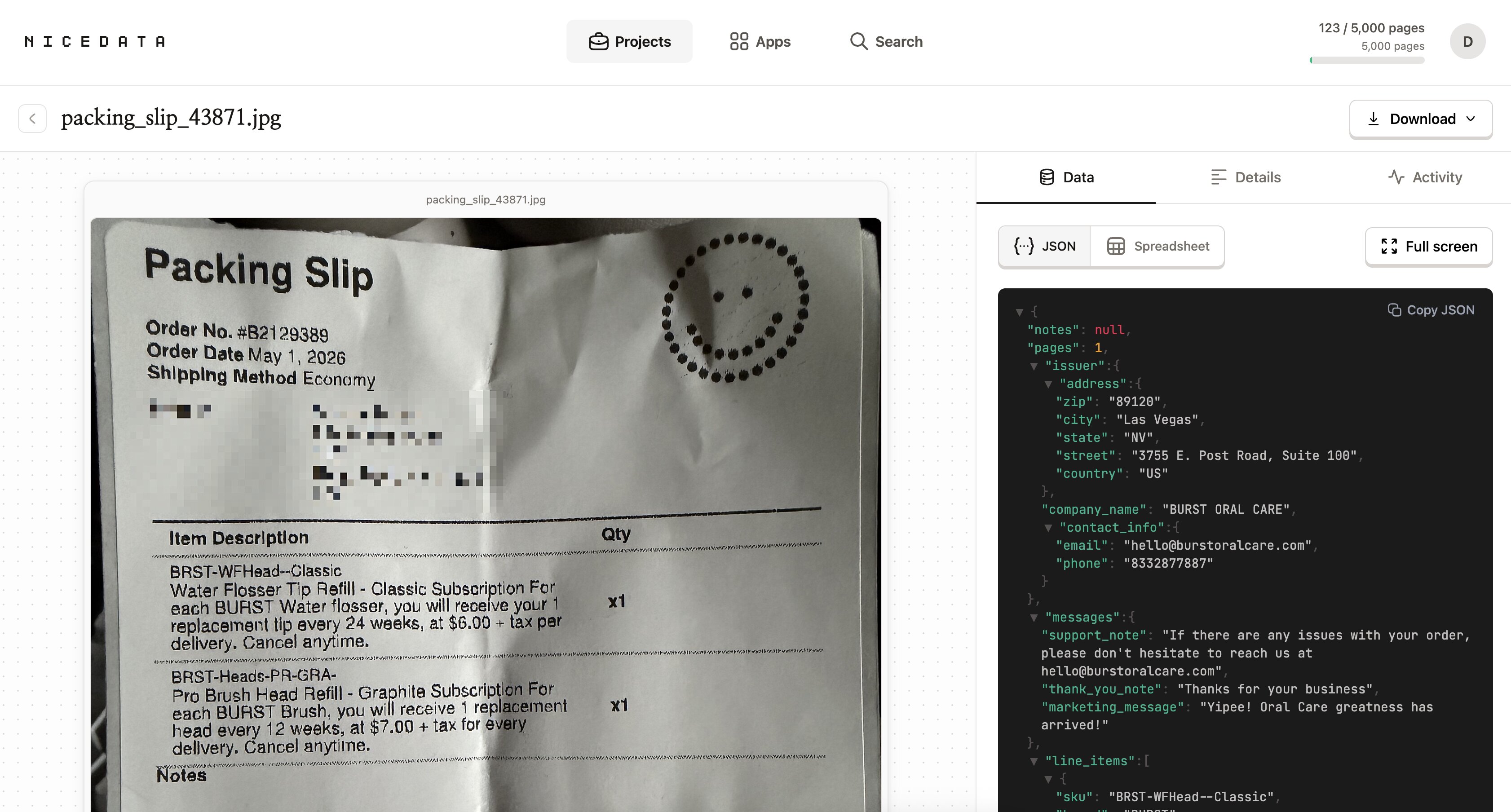
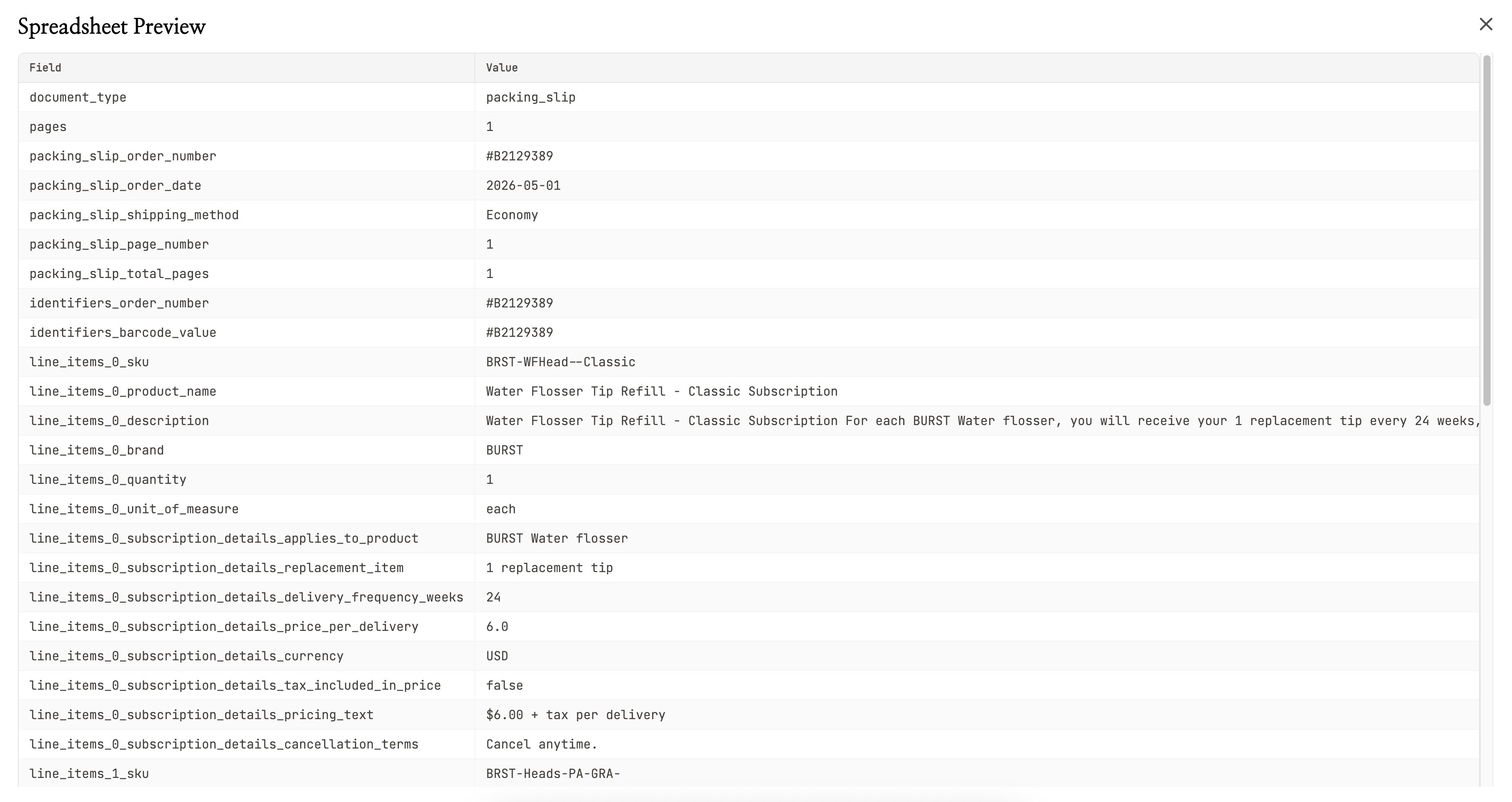
Dès que le téléversement est terminé, NiceData commence à lire l’image. Il utilise l’IA pour reconnaître chaque mot, chiffre, date et montant dans l’image, et organise ces informations en champs propres que vous pouvez réellement utiliser.
Vous n’avez pas à dessiner de cases autour du texte. Vous n’avez pas à lui indiquer où se trouve le total ou quelle ligne est la date. Il s’en occupe tout seul, même sur des documents qu’il n’a jamais vus.
La plupart des images sont traitées en moins d’une minute.
Étape 3 : Exportez vos données
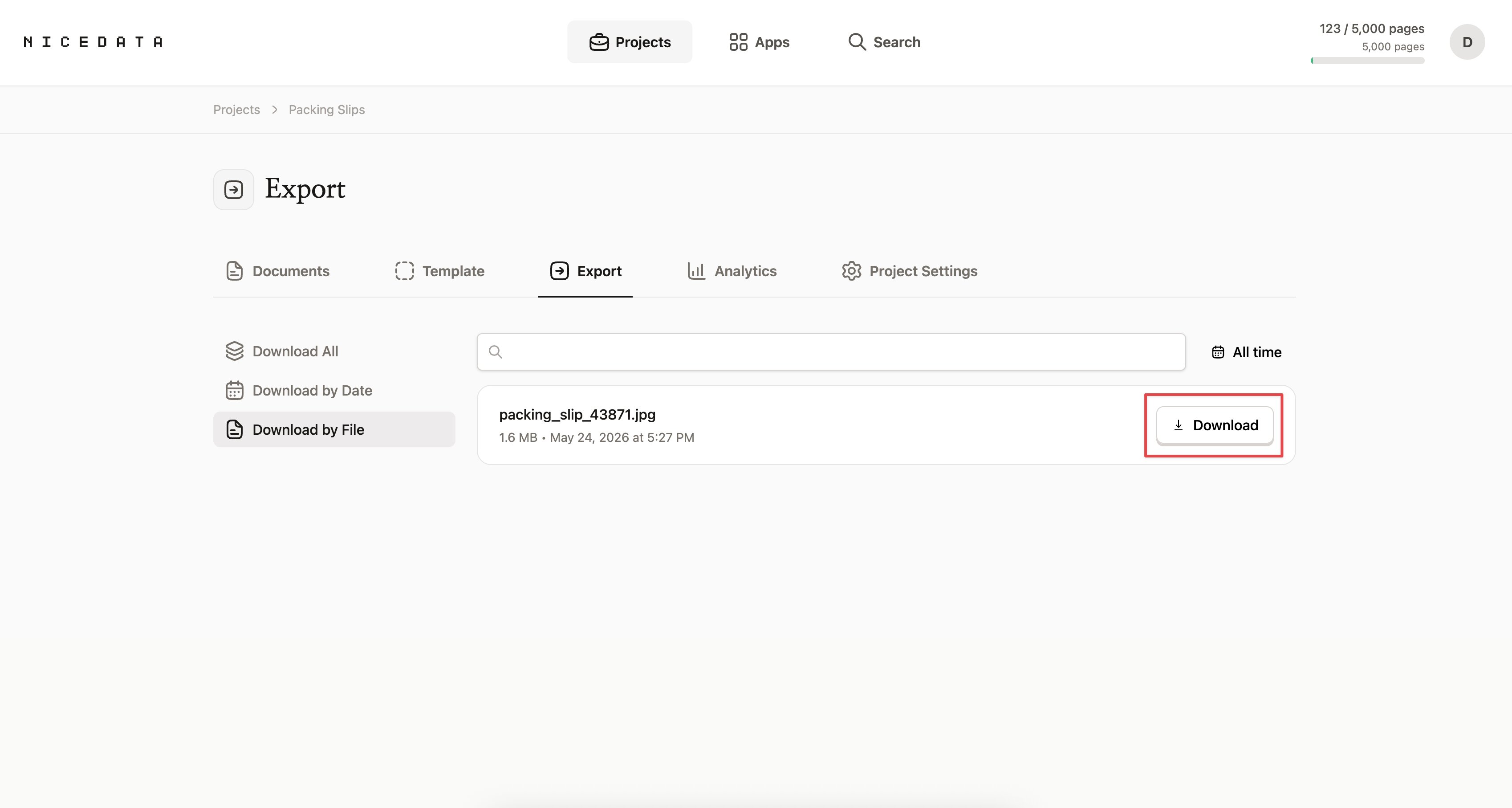
Une fois l’extraction terminée, vous avez plusieurs options :
- Consultez les données dans le tableau de bord NiceData et copiez ce dont vous avez besoin.
- Téléchargez en CSV pour ouvrir dans Excel, Google Sheets ou Numbers.
- Téléchargez en Excel avec des en-têtes déjà mis en forme et prêts à partager avec votre équipe.
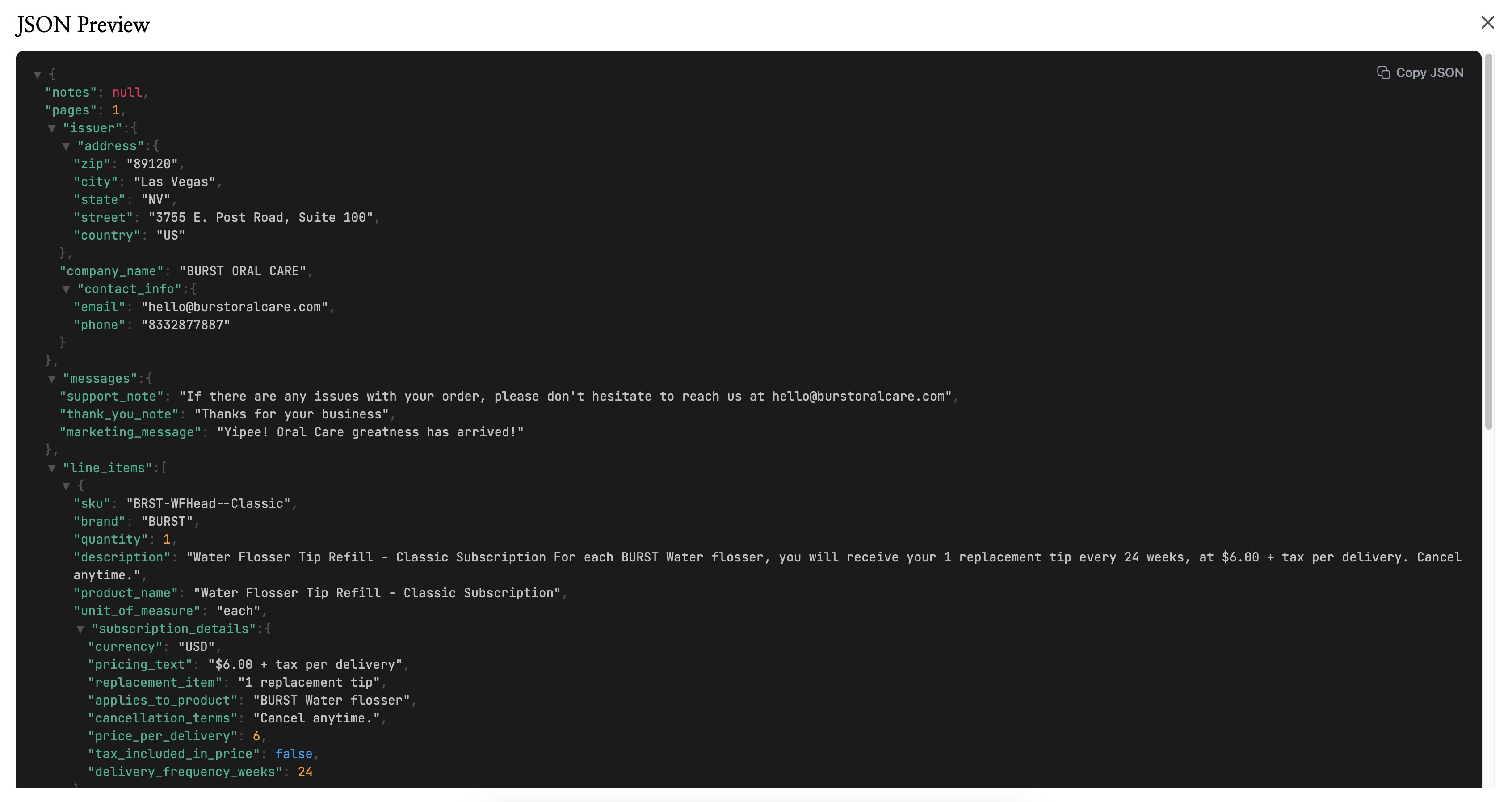
- Téléchargez en JSON si vous voulez transmettre les données à un développeur ou à un autre outil.
C’est tout. D’une photo sur votre téléphone à un tableur propre, en trois étapes.
Comment contrôler ce qui est extrait
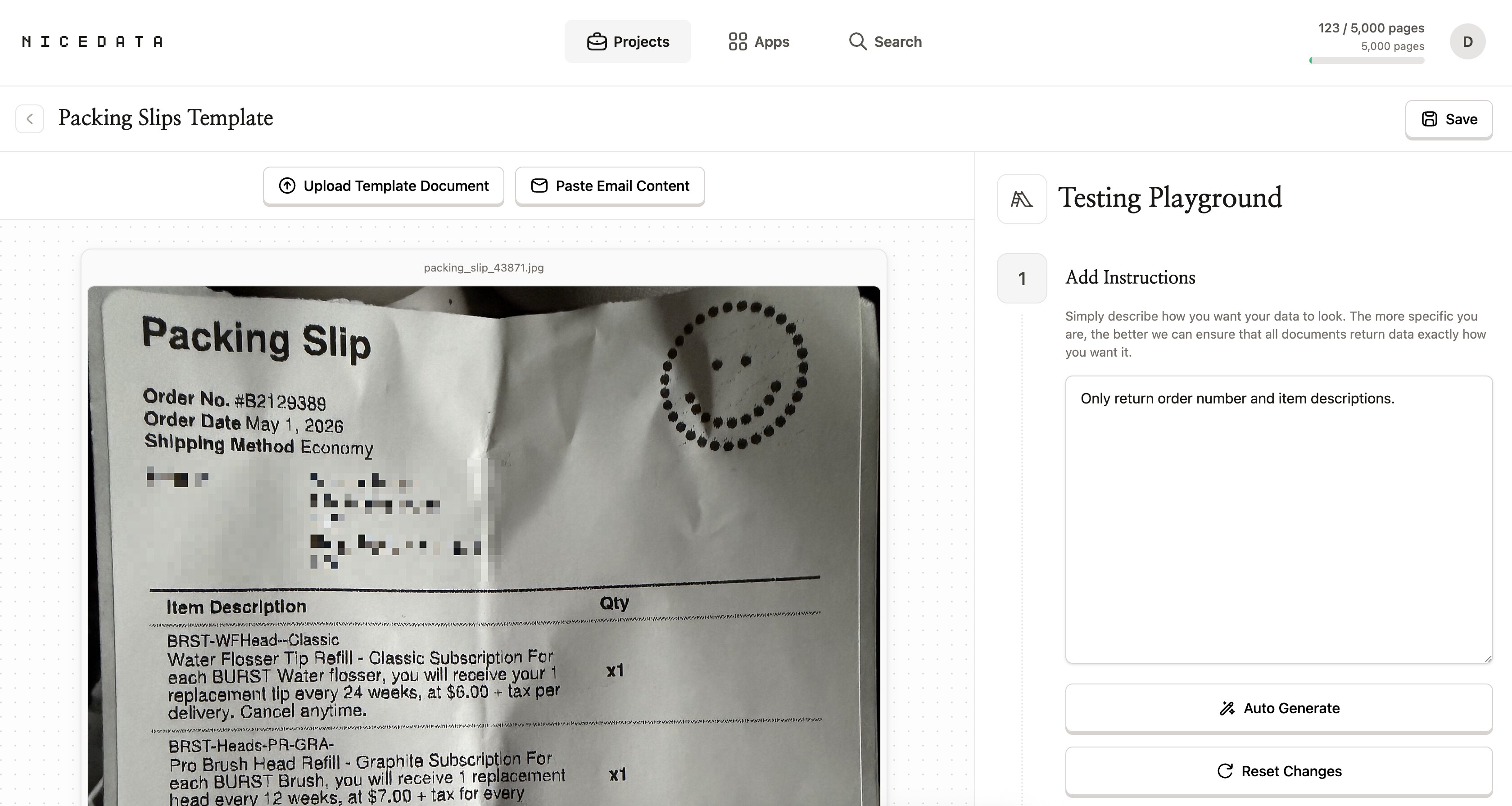
Par défaut, NiceData lit tout ce qu’il trouve dans votre image. Si vous n’avez besoin que de certains champs, comme uniquement le numéro de commande et les descriptions d’articles, vous pouvez le lui dire en langage naturel.
Ouvrez le Testing Playground de votre projet, tapez vos instructions dans la zone de texte (quelque chose comme « Only return order number and item descriptions. »), et NiceData utilisera ces instructions pour chaque image que vous téléverserez dans ce projet par la suite.
Aucune règle à écrire. Aucun champ à mapper. Aucun regex. Décrivez simplement ce que vous voulez et NiceData s’occupe du reste.
Pourquoi NiceData est la façon la plus simple de le faire
La plupart des outils qui promettent d’extraire du texte d’images vous obligent à travailler pour ça. Vous devez configurer des modèles pour chaque type de document. Vous devez entraîner un modèle sur des dizaines d’exemples avant qu’il devienne précis. Vous devez écrire des règles pour trouver des champs spécifiques, ou écrire du code pour appeler une API, ou créer un compte développeur juste pour lire un reçu.
NiceData saute toutes ces étapes. Vous téléversez une image, NiceData la lit, vous téléchargez le résultat. Rien à configurer, aucun modèle à maintenir, aucun code à écrire.
C’est ça, la différence. Les autres outils sont conçus pour de grandes équipes techniques. NiceData est conçu pour toute personne ayant un document et une échéance.
Quels types de fichiers vous pouvez téléverser
NiceData lit le texte dans tous les formats d’image et de document courants :
- JPG et JPEG (photos et scans)
- PNG (captures d’écran et images haute qualité)
- GIF
- WebP
- TIFF et TIF (souvent utilisés par les scanners)
- PDF (une page ou plusieurs)
Vous pouvez aussi téléverser des documents Word, des fichiers Excel et des CSV si vos données sont déjà dans l’un de ces formats. NiceData les traite tous de la même manière.
Comment exporter votre texte extrait
Une fois que NiceData a lu votre image, vous pouvez exporter le texte extrait dans le format qui convient le mieux à votre prochain usage.
- CSV est le bon choix si vous voulez ouvrir les données dans un tableur. Chaque champ devient une colonne, chaque document devient une ligne.
- Excel est idéal pour partager le fichier avec des collègues. Les en-têtes sont mis en forme, la mise en page est propre, et le fichier s’ouvre directement dans Microsoft Excel ou Google Sheets.
- JSON est le format préféré des développeurs. Si vous transmettez les données à un autre outil, une intégration ou une application personnalisée, JSON est le plus facile à utiliser.
- Copier depuis le tableau de bord est l’option la plus rapide pour les jobs uniques. Ouvrez le document dans NiceData, copiez les champs dont vous avez besoin, collez-les où vous voulez.
Vous pouvez mélanger les options. Exportez le même document en CSV pour votre équipe et en JSON pour votre développeur, sans étapes supplémentaires.
Questions fréquentes
Est-ce gratuit à essayer ?
Oui. NiceData propose un essai gratuit de 14 jours incluant 25 pages d'extraction. Sans carte bancaire. Vous pouvez le tester sur vos propres documents avant de décider de vous abonner.
Faut-il savoir coder ?
Non. NiceData est conçu pour les personnes qui n'ont jamais écrit une ligne de code de leur vie. Tout le flux de travail se passe dans votre navigateur, via une interface conviviale. Si vous savez glisser un fichier dans un dossier, vous savez utiliser NiceData.
Quelle est la précision de l'extraction de texte ?
Très précise, d'après notre expérience. NiceData utilise une IA moderne pour lire le texte, donc il gère bien les documents imprimés, les scans, les photos et même la plupart des notes manuscrites. La précision tient sur des documents dans n'importe quelle langue, y compris ceux qui mélangent texte et chiffres comme les factures et les reçus.
Quelles langues sont prises en charge ?
Toutes les langues. NiceData lit le texte en français, anglais, espagnol, allemand, italien, portugais, japonais, coréen, chinois, et des dizaines d'autres. Pas besoin de lui indiquer la langue du document. Il la détecte automatiquement.
Peut-il gérer les PDF de plusieurs pages ?
Oui. Téléversez un PDF multi-pages et NiceData lit chaque page. Chaque page compte pour une page sur votre forfait mensuel, donc un document de 10 pages utilise 10 pages de votre quota.
Mes données sont-elles sécurisées ?
Oui. Vos documents sont chiffrés en transit et au repos, et stockés dans des dossiers de projet isolés auxquels seuls vous et votre équipe avez accès. Vous pouvez aussi configurer la suppression automatique des documents après 1, 14, 30, 60 ou 90 jours.

Dace Willmott
Founder
NiceData aims to eliminate manual data entry from document workflows. We write about AI-powered document processing, data extraction best practices, and the tools that help teams move faster with cleaner data.