이미지에서 텍스트 추출하는 방법
영수증, 청구서, 명함, 또는 텍스트로 가득 찬 스크린샷 사진이 있다면, 그 안의 모든 단어를 몇 초 만에 뽑아낼 수 있습니다. 하나하나 손으로 다시 칠 필요도 없고, 복잡한 소프트웨어를 설정할 필요도 없고, 템플릿을 그릴 필요도 없습니다.
이 가이드는 NiceData로 이미지에서 텍스트를 추출하는 방법을 안내합니다. NiceData는 모든 문서를 깔끔한 구조화 데이터로 바꾸는 가장 간단한 방법이며, 스프레드시트, 데이터베이스, 그 어디에든 바로 사용할 수 있습니다.
왜 이미지에서 텍스트를 추출하나요?
대부분의 팀이 매주 몇 시간을 이미 이미지나 PDF에 있는 정보를 다시 입력하는 데 씁니다. 흔한 예시:
- 영수증 (경비 보고용)
- 청구서 (거래처에서 받은 것)
- 명함 (행사에서 모은 것)
- 손글씨 메모 (회의에서 적은 것)
- 스크린샷 (이메일이나 웹페이지)
- 스캔한 양식 (고객이 작성한 것)
- 화이트보드 사진 (브레인스토밍 후)
수동으로 처리하면 느리고 오류가 많습니다. 자동으로 추출하면 같은 데이터를 몇 초 만에 얻을 수 있고, 바로 스프레드시트에 넣거나 회계 도구로 보낼 수 있습니다.
NiceData로 이미지에서 텍스트 추출하는 방법
세 단계입니다. 전체 과정이 이게 전부입니다.
1단계: 이미지 업로드
NiceData에 로그인하고 이미지를 업로드 영역에 끌어다 놓으세요. 파일 하나든, 수백 개든 한 번에 던져 넣을 수 있습니다. NiceData는 JPG, PNG, GIF, WebP, TIFF 이미지를 받고, 스캔본이 PDF라면 PDF도 받습니다.
이미지를 미리 자르거나 회전시키거나 정리할 필요는 없습니다. 휴대폰으로 찍은 사진도 잘 됩니다. 살짝 흐릿한 스캔본도 잘 됩니다. 텍스트, 표, 로고가 섞인 페이지도 잘 됩니다.
2단계: NiceData가 읽도록 두기
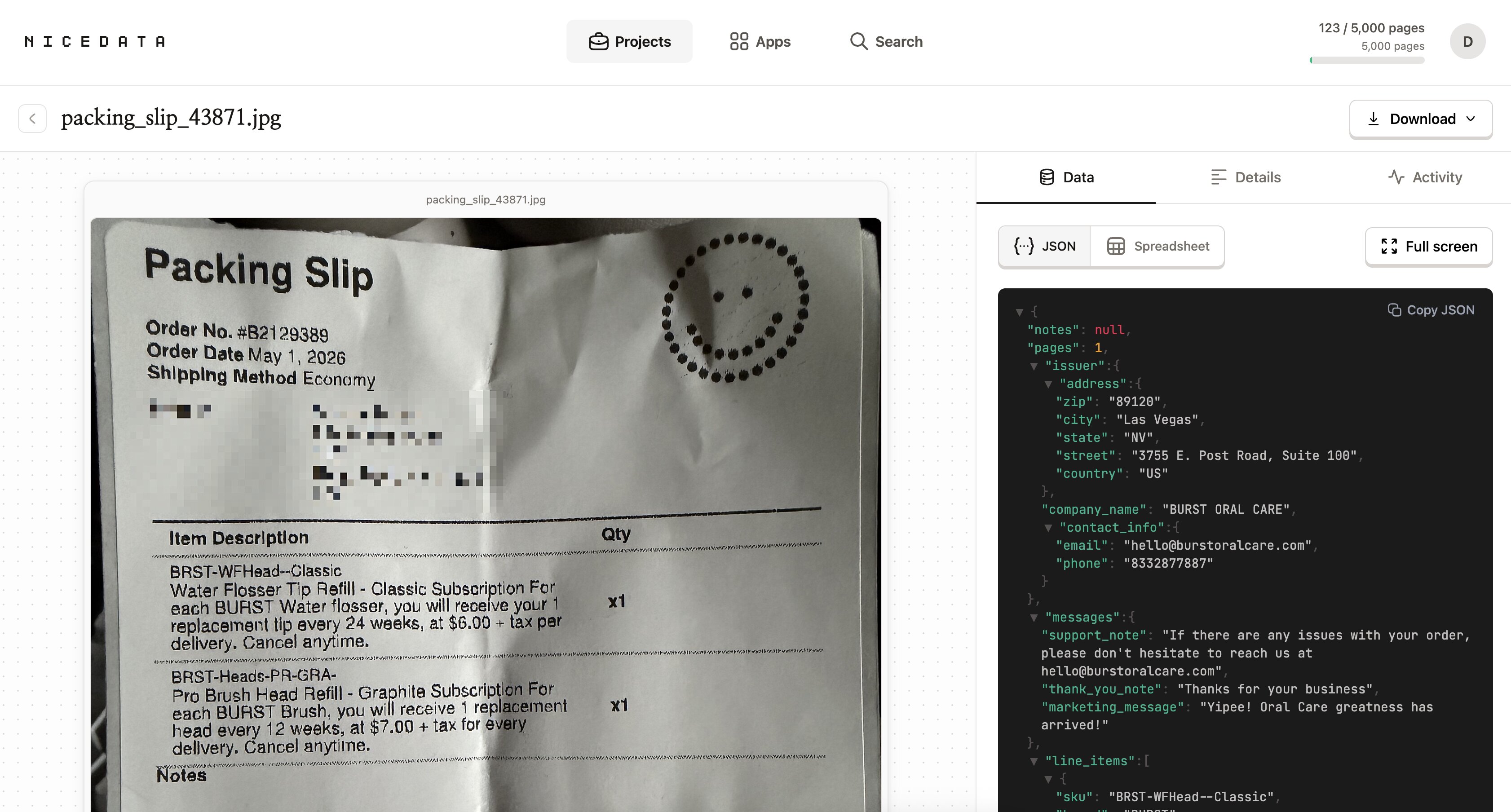
업로드가 끝나는 즉시 NiceData가 이미지를 읽기 시작합니다. AI가 이미지 속 모든 단어, 숫자, 날짜, 금액을 인식해서 실제로 쓸 수 있는 깔끔한 필드로 정리해줍니다.
텍스트 주변에 박스를 그릴 필요가 없습니다. 합계가 어디 있는지, 어느 줄이 날짜인지 알려줄 필요도 없습니다. 처음 보는 문서라도 알아서 다 파악합니다.
대부분의 이미지는 1분 안에 처리가 끝납니다.
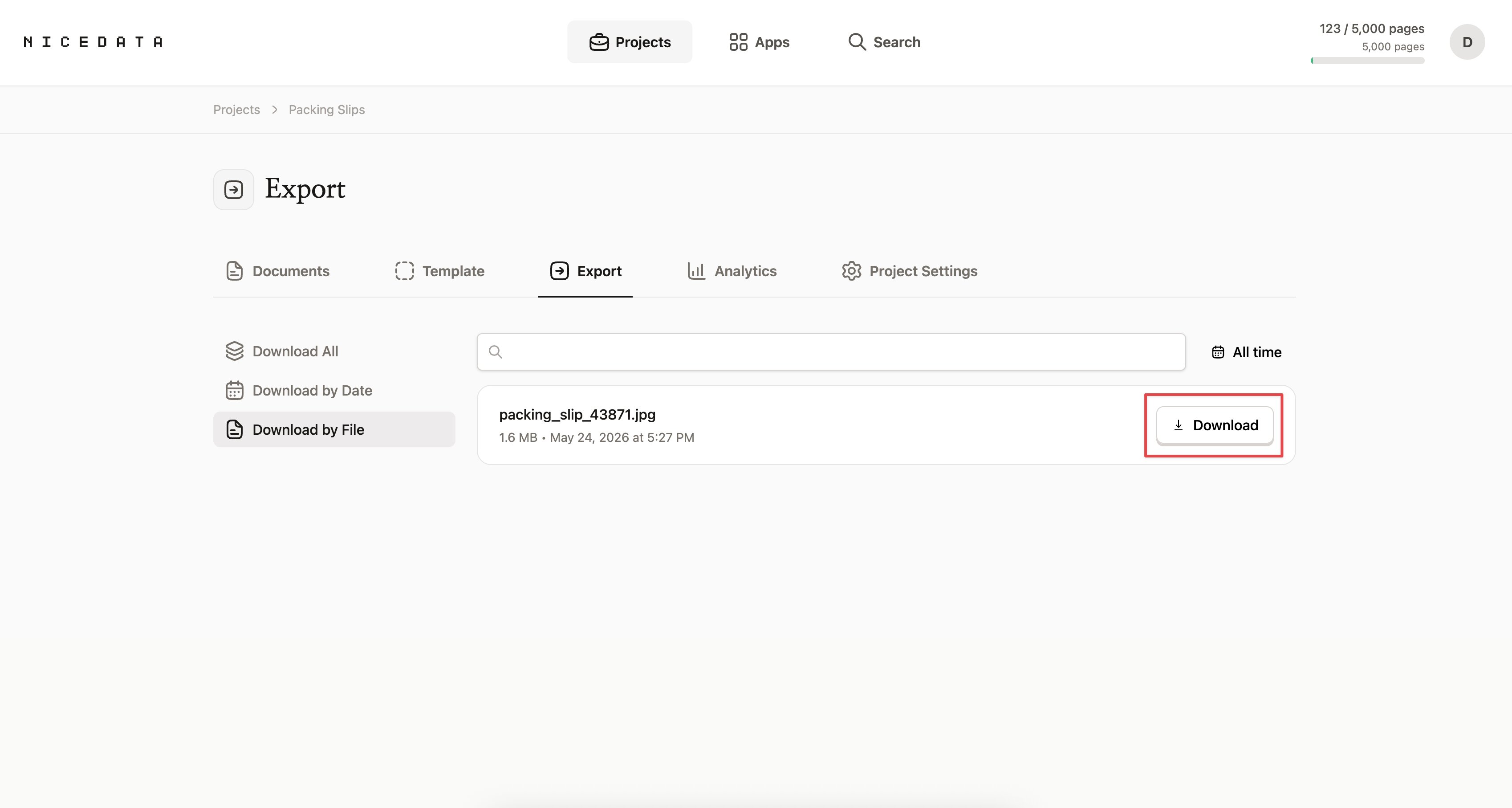
3단계: 데이터 내보내기
추출이 끝나면 몇 가지 선택지가 있습니다:
- NiceData 대시보드에서 데이터 확인 후 필요한 부분 복사하기.
- CSV로 다운로드해서 Excel, Google 스프레드시트, Numbers로 열기.
- Excel 파일로 다운로드해서 헤더가 이미 정리된 상태로 팀과 공유하기.
- JSON으로 다운로드해서 개발자나 다른 도구로 넘기기.
이게 끝입니다. 휴대폰 속 사진에서 깔끔한 스프레드시트까지, 세 단계로.
추출되는 내용을 제어하는 방법
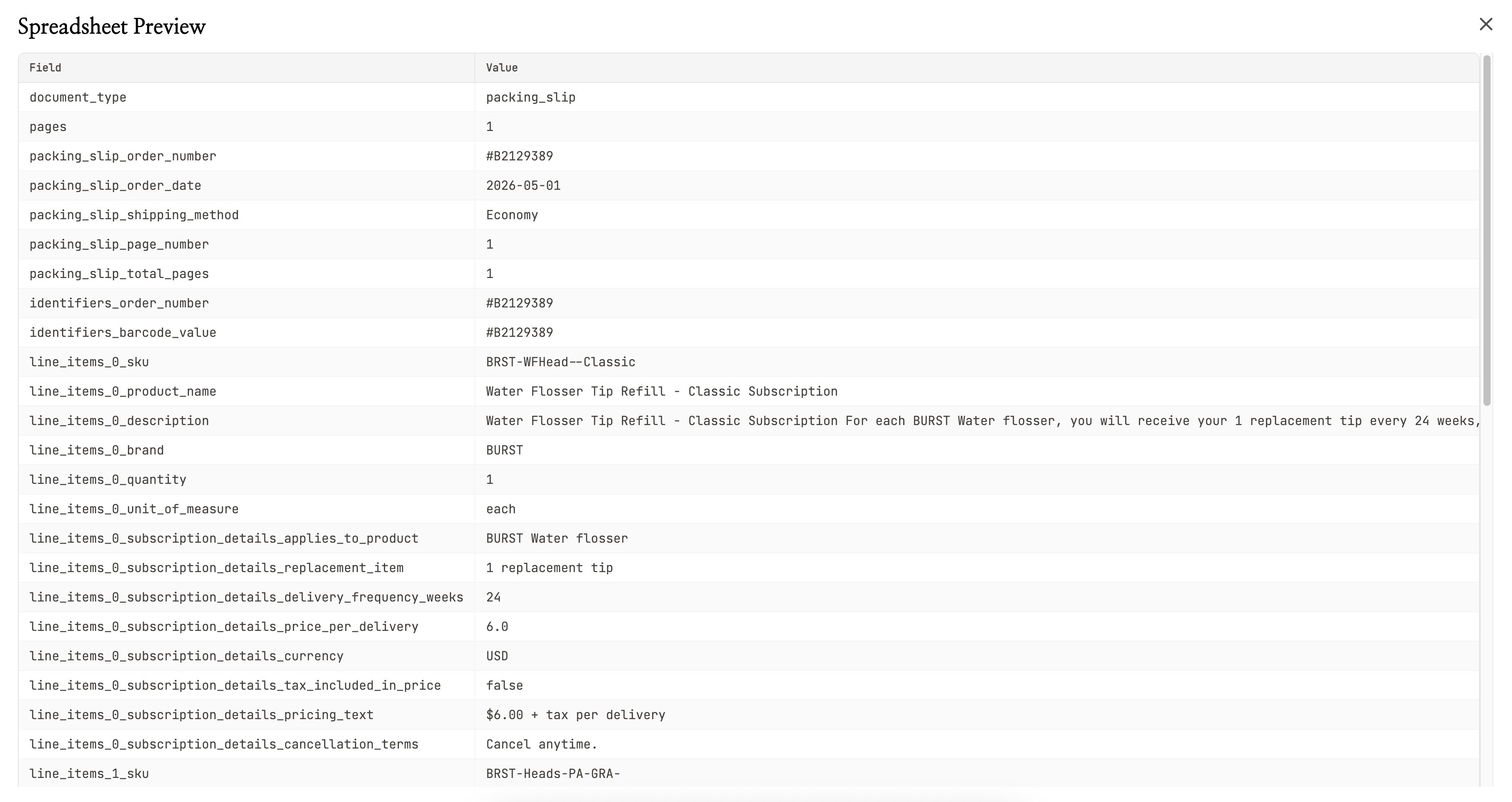
NiceData는 기본적으로 이미지에서 찾을 수 있는 모든 것을 읽습니다. 주문 번호와 품목 설명처럼 특정 항목만 필요하다면, 자연스러운 말로 알려주면 됩니다.
프로젝트의 Testing Playground를 열고 텍스트 상자에 지시 사항을 입력하세요 (예: “Only return order number and item descriptions.”). 그러면 이후 그 프로젝트에 업로드하는 모든 이미지에 대해 NiceData가 그 지시를 적용합니다.
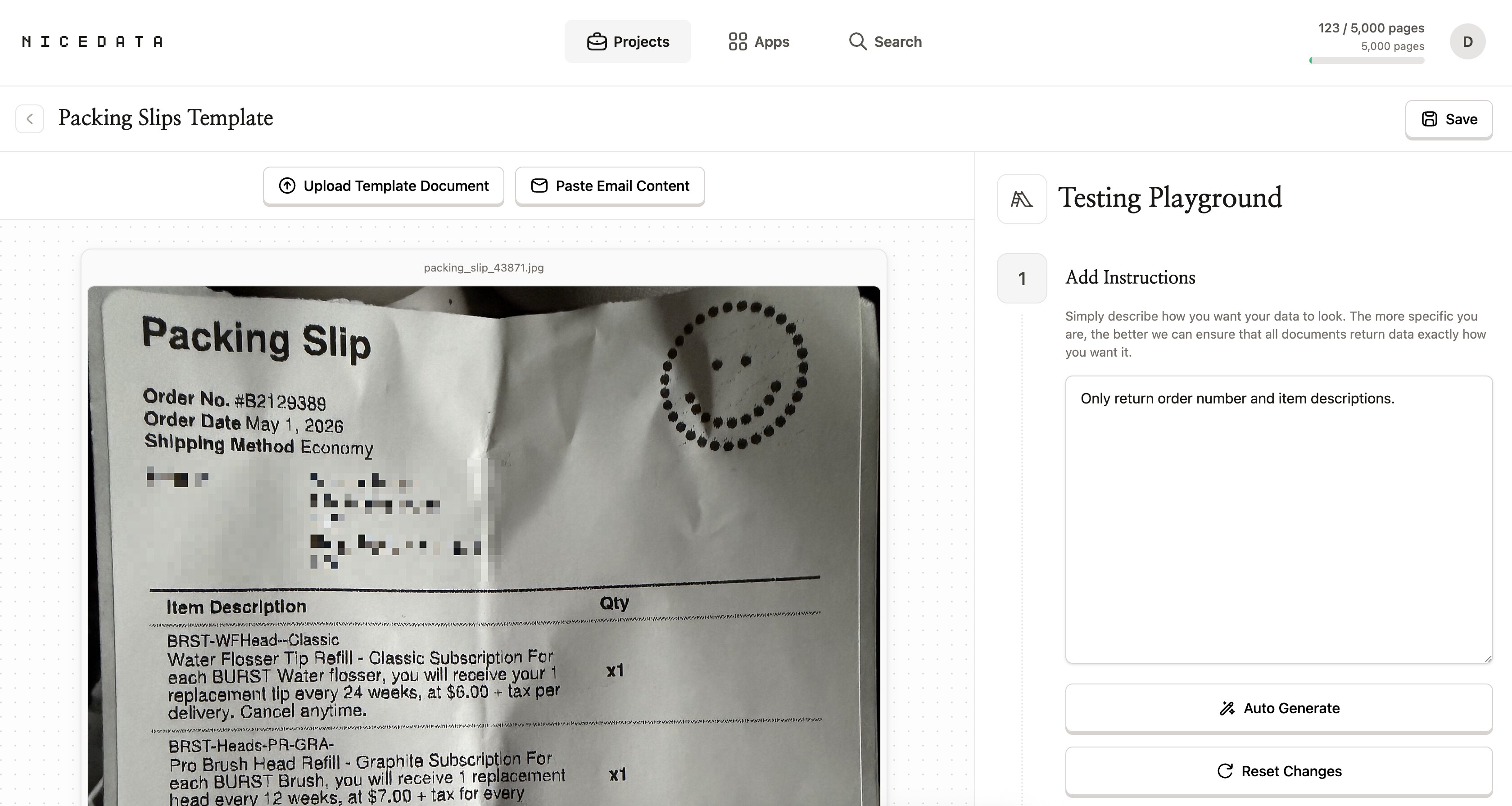
규칙을 쓸 필요도, 필드를 매핑할 필요도, 정규식도 필요 없습니다. 원하는 결과를 설명하기만 하면 나머지는 NiceData가 알아서 합니다.
왜 NiceData가 가장 간단한가
이미지에서 텍스트를 추출해준다는 대부분의 도구는 사용자에게 일을 시킵니다. 문서 유형마다 템플릿을 만들어야 합니다. 정확도를 내려면 수십 개의 예시로 모델을 학습시켜야 합니다. 특정 필드를 찾는 규칙을 작성해야 하거나, API를 호출하는 코드를 써야 하거나, 영수증 하나 읽으려고 개발자 계정을 만들어야 합니다.
NiceData는 그걸 다 건너뜁니다. 이미지를 업로드하고, NiceData가 읽고, 결과를 다운로드합니다. 설정할 것도, 유지할 템플릿도, 작성할 코드도 없습니다.
차이가 여기 있습니다. 다른 도구들은 대규모 기술 팀을 위해 만들어졌습니다. NiceData는 문서와 마감일을 가진 모든 사람을 위해 만들어졌습니다.
업로드할 수 있는 파일 형식
NiceData는 일반적인 이미지와 문서 형식 모두에서 텍스트를 읽어냅니다:
- JPG와 JPEG (사진과 스캔본)
- PNG (스크린샷과 고화질 이미지)
- GIF
- WebP
- TIFF와 TIF (스캐너에서 자주 쓰임)
- PDF (한 페이지 또는 여러 페이지)
데이터가 이미 Word, Excel, CSV 중 하나로 되어 있다면 그것들도 업로드할 수 있습니다. NiceData는 모두 똑같이 처리합니다.
추출한 텍스트를 내보내는 방법
NiceData가 이미지를 읽고 나면, 다음에 하려는 작업에 가장 잘 맞는 형식으로 추출된 텍스트를 내보낼 수 있습니다.
- CSV는 데이터를 스프레드시트에서 열고 싶을 때 적합합니다. 필드마다 열이 되고, 문서마다 행이 됩니다.
- Excel은 파일을 동료와 공유할 때 가장 좋습니다. 헤더가 정리되어 있고, 레이아웃이 깔끔하며, Microsoft Excel이나 Google 스프레드시트에서 바로 열립니다.
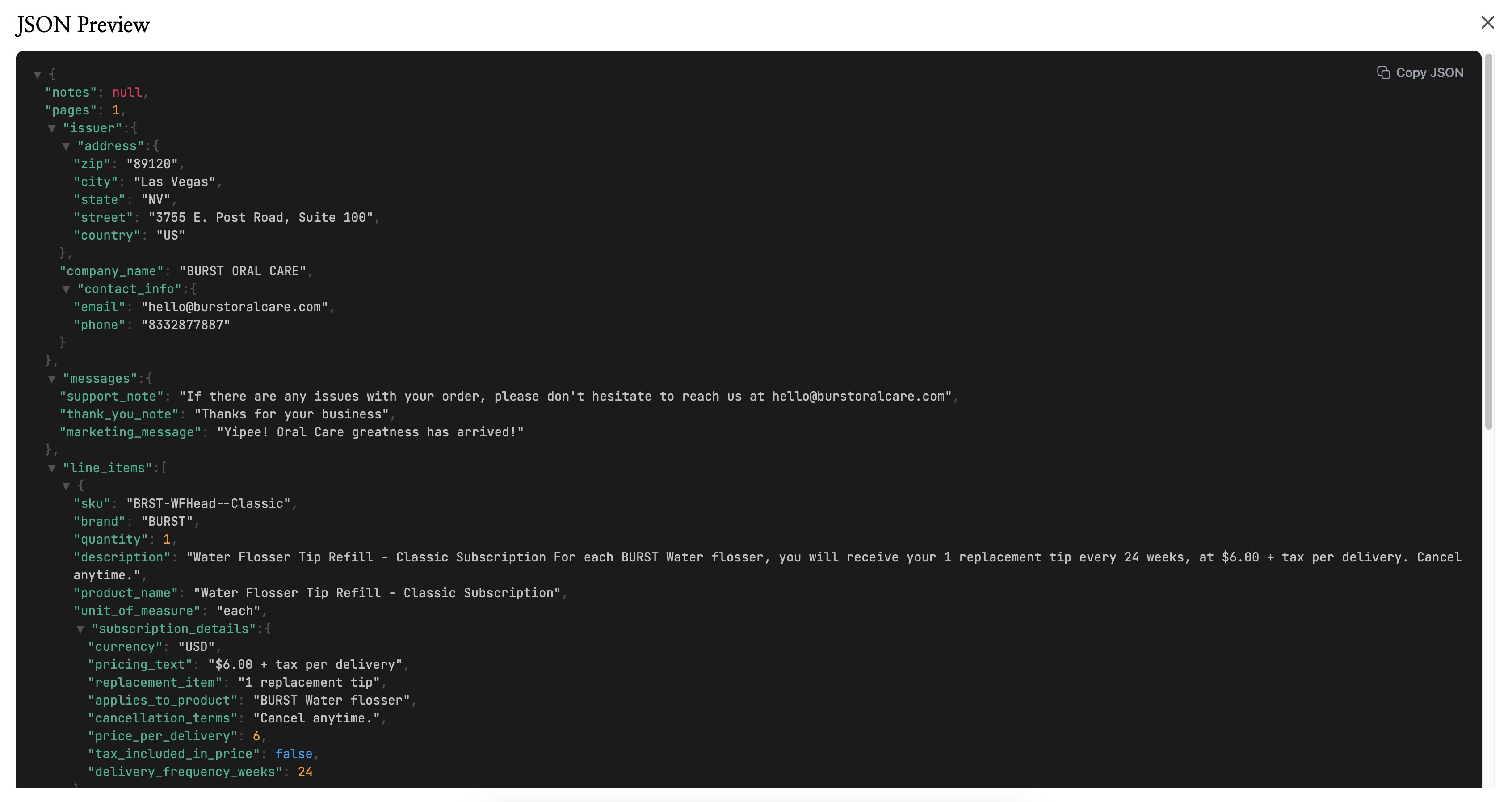
- JSON은 개발자들이 선호하는 형식입니다. 데이터를 다른 도구, 연동, 또는 자체 앱에 넘긴다면 JSON이 다루기 가장 쉽습니다.
- 대시보드에서 복사는 일회성 작업에 가장 빠른 방법입니다. NiceData에서 문서를 열고, 필요한 필드를 복사해서, 원하는 곳에 붙여 넣으세요.
섞어 써도 됩니다. 같은 문서를 팀용으로는 CSV, 개발자용으로는 JSON으로 내보낼 수 있습니다. 추가 단계 없이요.
자주 묻는 질문
무료로 써볼 수 있나요?
네. NiceData는 25페이지 추출이 포함된 14일 무료 체험을 제공합니다. 신용카드는 필요 없습니다. 구독을 결정하기 전에 자신의 문서로 직접 테스트할 수 있습니다.
코딩을 알아야 하나요?
아니요. NiceData는 코드 한 줄 작성해본 적 없는 분들을 위해 설계되었습니다. 전체 작업이 브라우저에서, 친근한 인터페이스로 진행됩니다. 파일을 폴더로 끌어다 놓을 수 있다면 NiceData를 쓸 수 있습니다.
텍스트 추출이 얼마나 정확한가요?
저희 경험상 매우 정확합니다. NiceData는 최신 AI로 텍스트를 읽기 때문에 인쇄된 문서, 스캔본, 사진, 그리고 대부분의 손글씨 메모까지 잘 처리합니다. 청구서나 영수증처럼 텍스트와 숫자가 섞인 문서나, 어떤 언어로 된 문서에서도 정확도가 유지됩니다.
어떤 언어를 지원하나요?
모든 언어입니다. NiceData는 한국어, 영어, 프랑스어, 스페인어, 독일어, 이탈리아어, 포르투갈어, 일본어, 중국어와 수십 개의 다른 언어로 된 텍스트를 읽을 수 있습니다. 문서가 어떤 언어인지 알려줄 필요가 없습니다. 자동으로 인식합니다.
여러 페이지 PDF도 처리할 수 있나요?
네. 여러 페이지 PDF를 업로드하면 NiceData가 모든 페이지를 읽습니다. 각 페이지는 월간 요금제의 1페이지로 계산되므로 10페이지 문서는 할당량의 10페이지를 사용합니다.
제 데이터는 안전한가요?
네. 문서는 전송 중과 보관 중 모두 암호화되며, 본인과 팀만 접근할 수 있는 격리된 프로젝트 폴더에 저장됩니다. 문서를 1일, 14일, 30일, 60일, 90일 후에 자동 삭제되도록 설정할 수도 있습니다.

Dace Willmott
Founder
NiceData aims to eliminate manual data entry from document workflows. We write about AI-powered document processing, data extraction best practices, and the tools that help teams move faster with cleaner data.