画像からテキストを抽出する方法
領収書、請求書、名刺、テキストがびっしり写ったスクリーンショットなど、画像があれば、その中の文字を数秒ですべて取り出せます。手で打ち直す必要はありません。面倒なソフトを設定する必要もありません。テンプレートを描く必要もありません。
このガイドでは、NiceData を使って画像からテキストを抽出する方法を紹介します。NiceData は、あらゆる書類をきれいな構造化データに変える一番シンプルな方法で、表計算ソフトやデータベース、その他どこにでもそのまま使えます。
なぜ画像からテキストを抽出するのか
多くのチームは、すでに画像や PDF の中に存在する情報を、毎週何時間もかけて打ち直しています。よくある例:
- 領収書(経費精算用)
- 請求書(取引先からのもの)
- 名刺(イベントで集めたもの)
- 手書きのメモ(会議のもの)
- スクリーンショット(メールや Web ページのもの)
- スキャンしたフォーム(お客様が記入したもの)
- ホワイトボードの写真(ブレインストーミングのあと)
手作業は遅くて、間違いも起きやすいです。自動で抽出すれば、同じデータが数秒で手に入り、そのまま表計算ソフトや会計ツールに渡せます。
NiceData で画像からテキストを抽出する方法
手順は 3 つです。それで全部です。
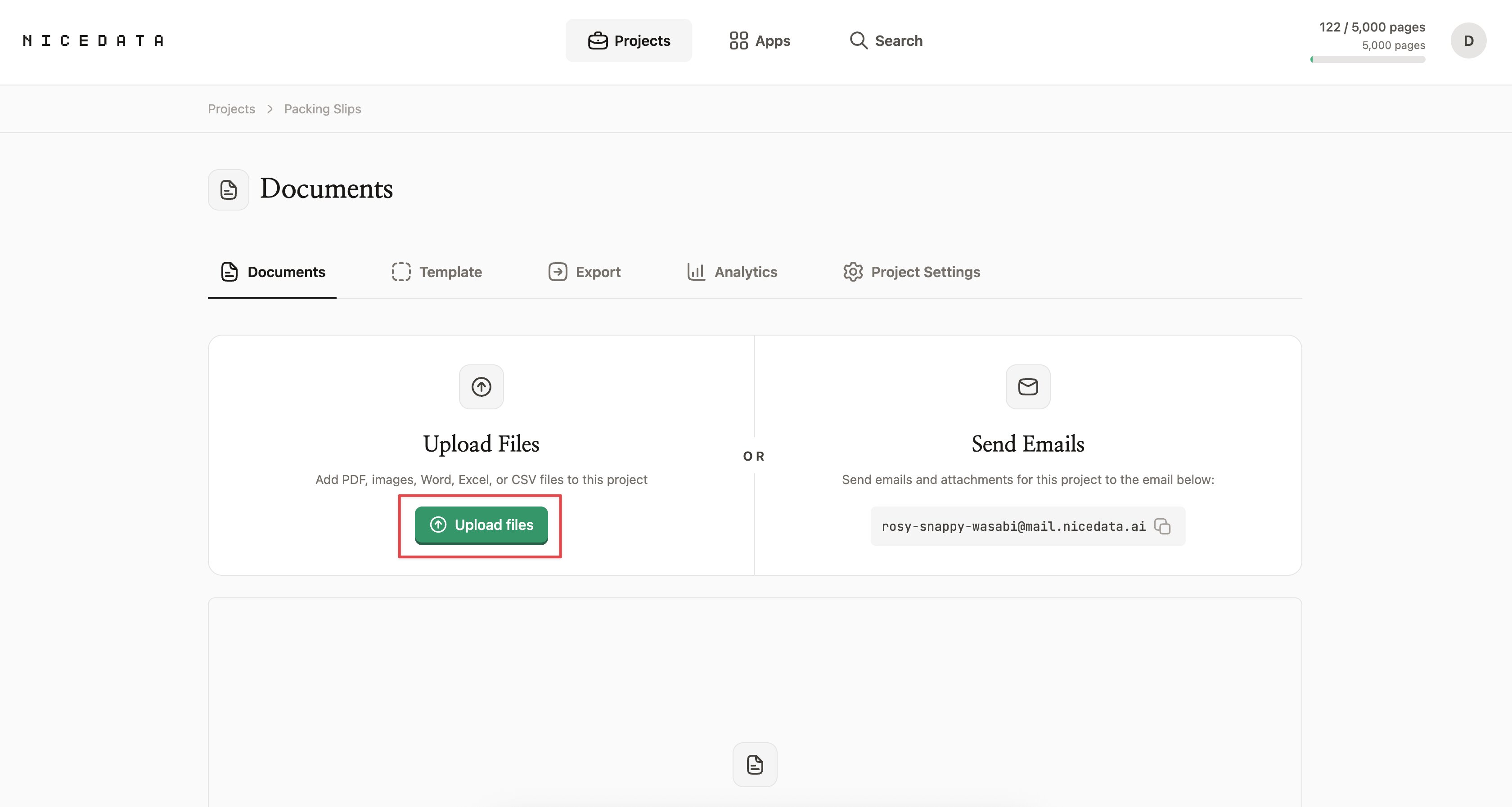
ステップ 1:画像をアップロードする
NiceData にサインインして、画像をアップロードエリアにドラッグします。1 ファイルでも数百ファイルでも一度に投げ込めます。NiceData は JPG、PNG、GIF、WebP、TIFF の画像に対応していて、スキャンが PDF 形式ならそれも使えます。
事前に画像をトリミングしたり、回転させたり、整える必要はありません。スマートフォンで撮った写真でも問題ありません。少しぼやけたスキャンでも問題ありません。テキスト、表、ロゴが混在したページでも問題ありません。
ステップ 2:NiceData に読ませる
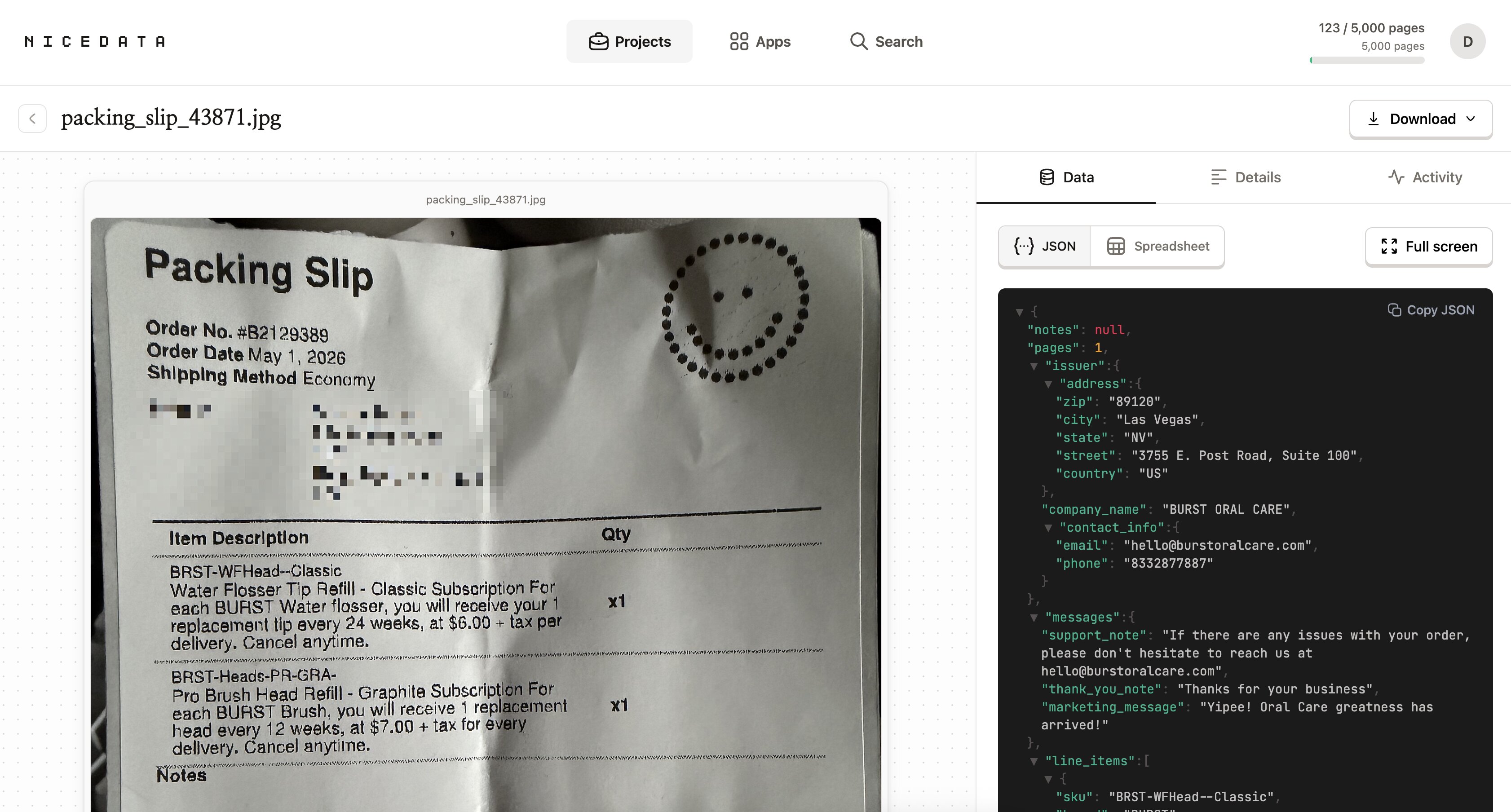
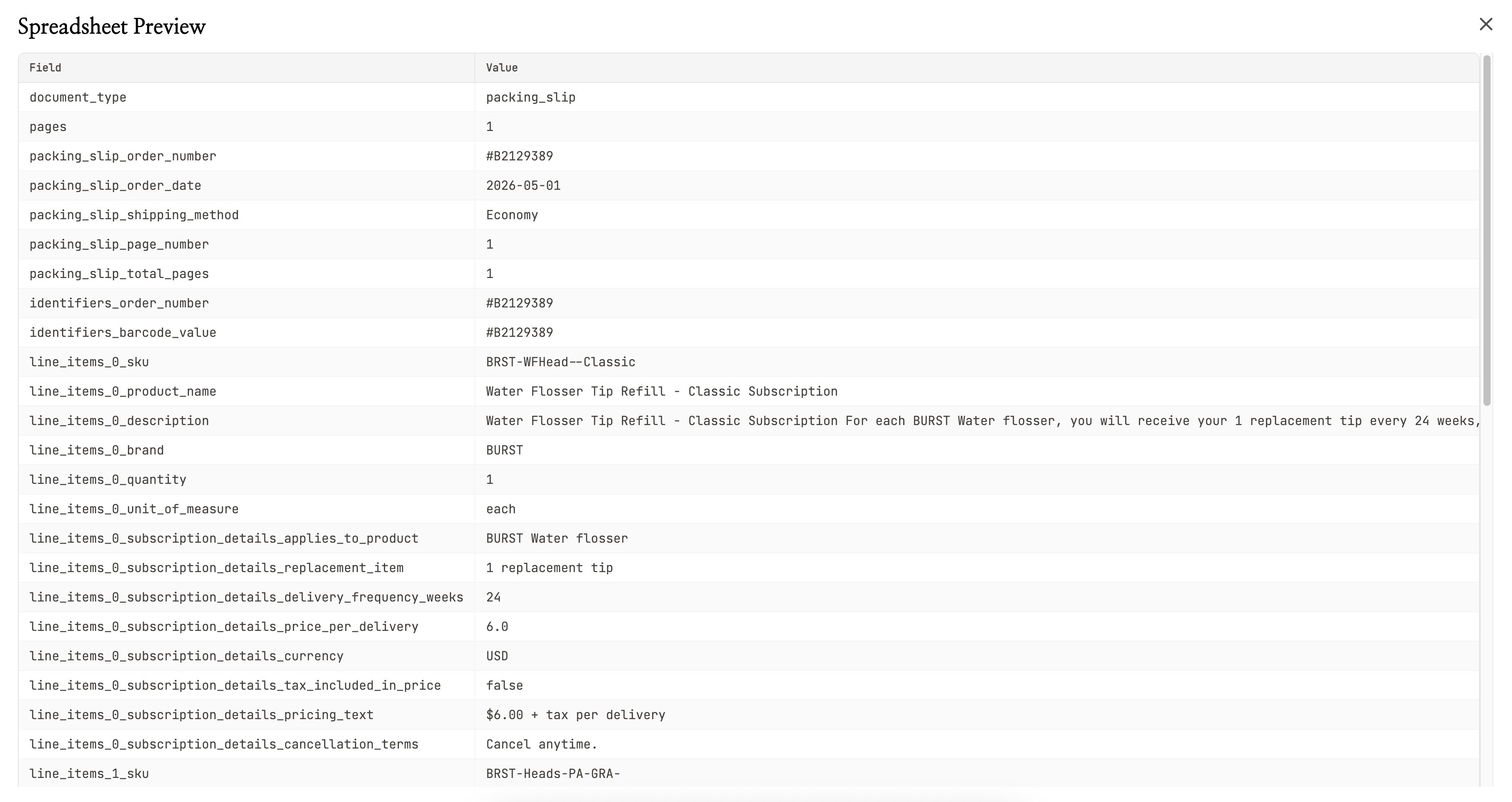
アップロードが終わると、NiceData がすぐに画像を読み始めます。AI が画像の中の単語、数字、日付、金額をすべて認識して、そのまま使えるきれいなフィールドに整理してくれます。
文字の周りに枠を描く必要はありません。合計がどこにあるか、どの行が日付かを指定する必要もありません。見たことのない書類でも、すべて自動で判断します。
ほとんどの画像は 1 分以内に処理が終わります。
ステップ 3:データを書き出す
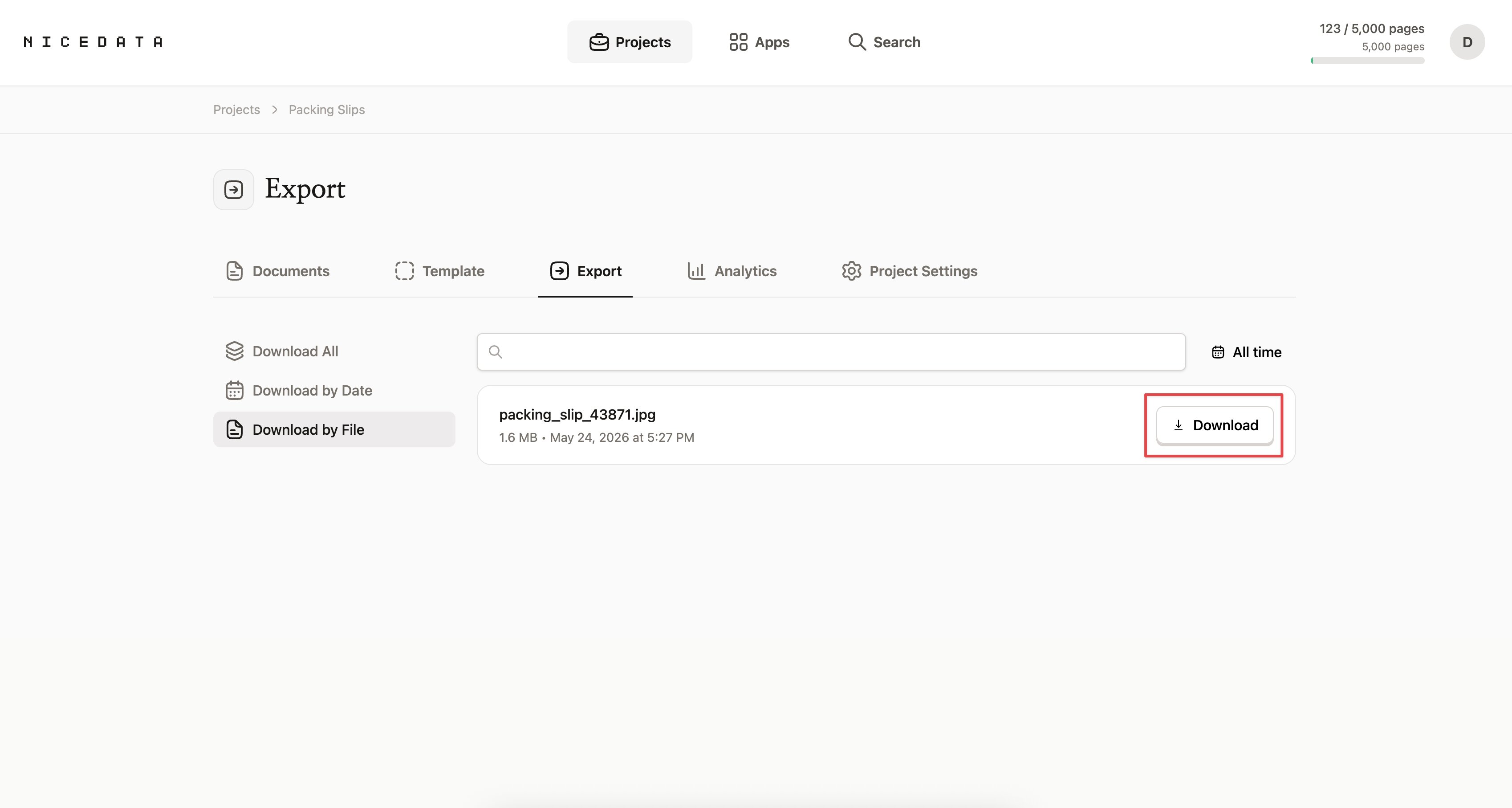
抽出が終わったら、いくつかの選択肢があります:
- NiceData のダッシュボードでデータを確認し、必要な部分をコピーする。
- CSV でダウンロードして、Excel、Google スプレッドシート、Numbers で開く。
- Excel でダウンロードして、見出しが整った状態でチームに共有する。
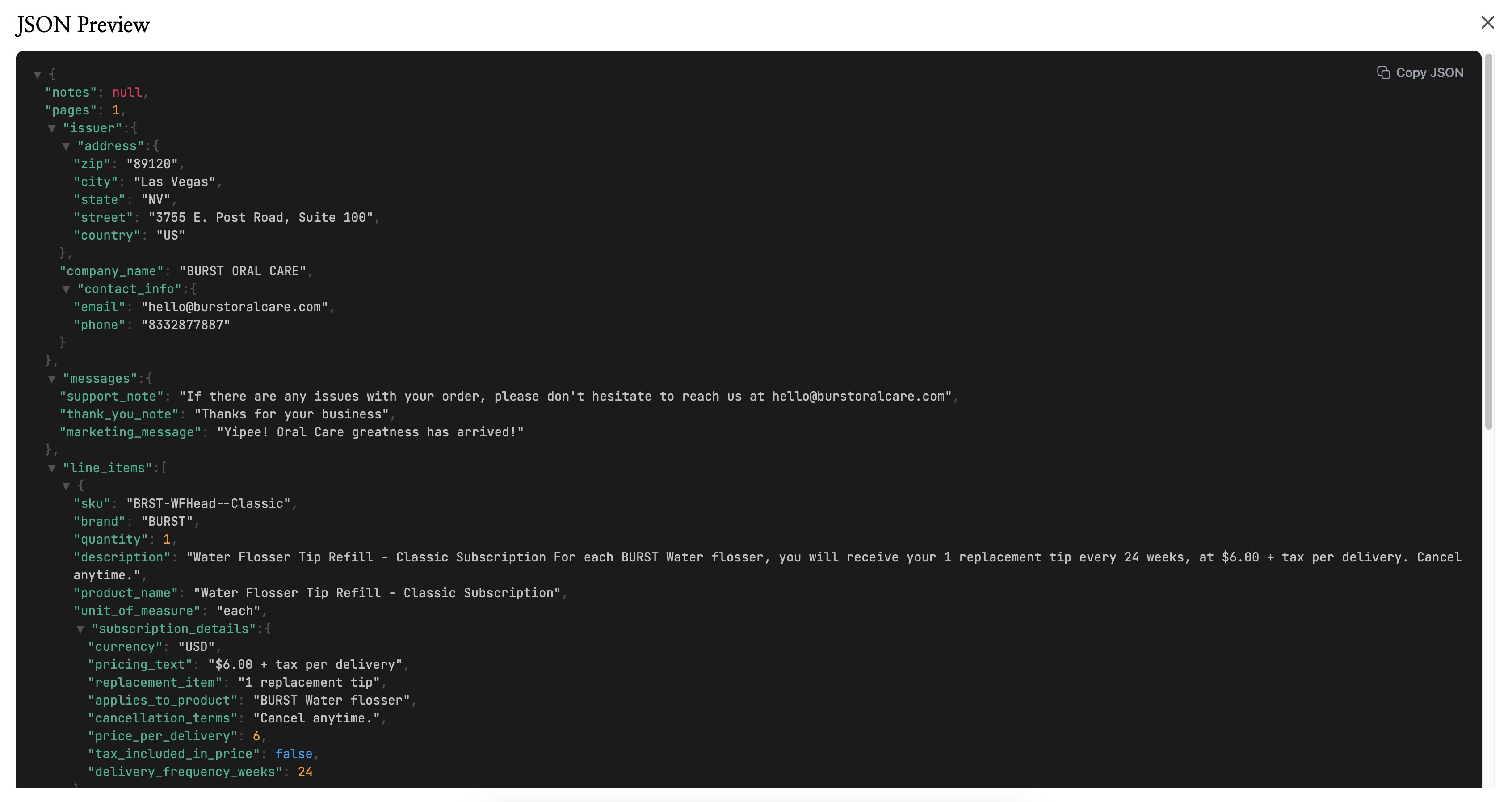
- JSON でダウンロードして、開発者や別のツールに渡す。
これで終わりです。スマートフォンの写真からきれいな表計算ファイルまで、3 ステップで完了です。
抽出される内容を制御する方法
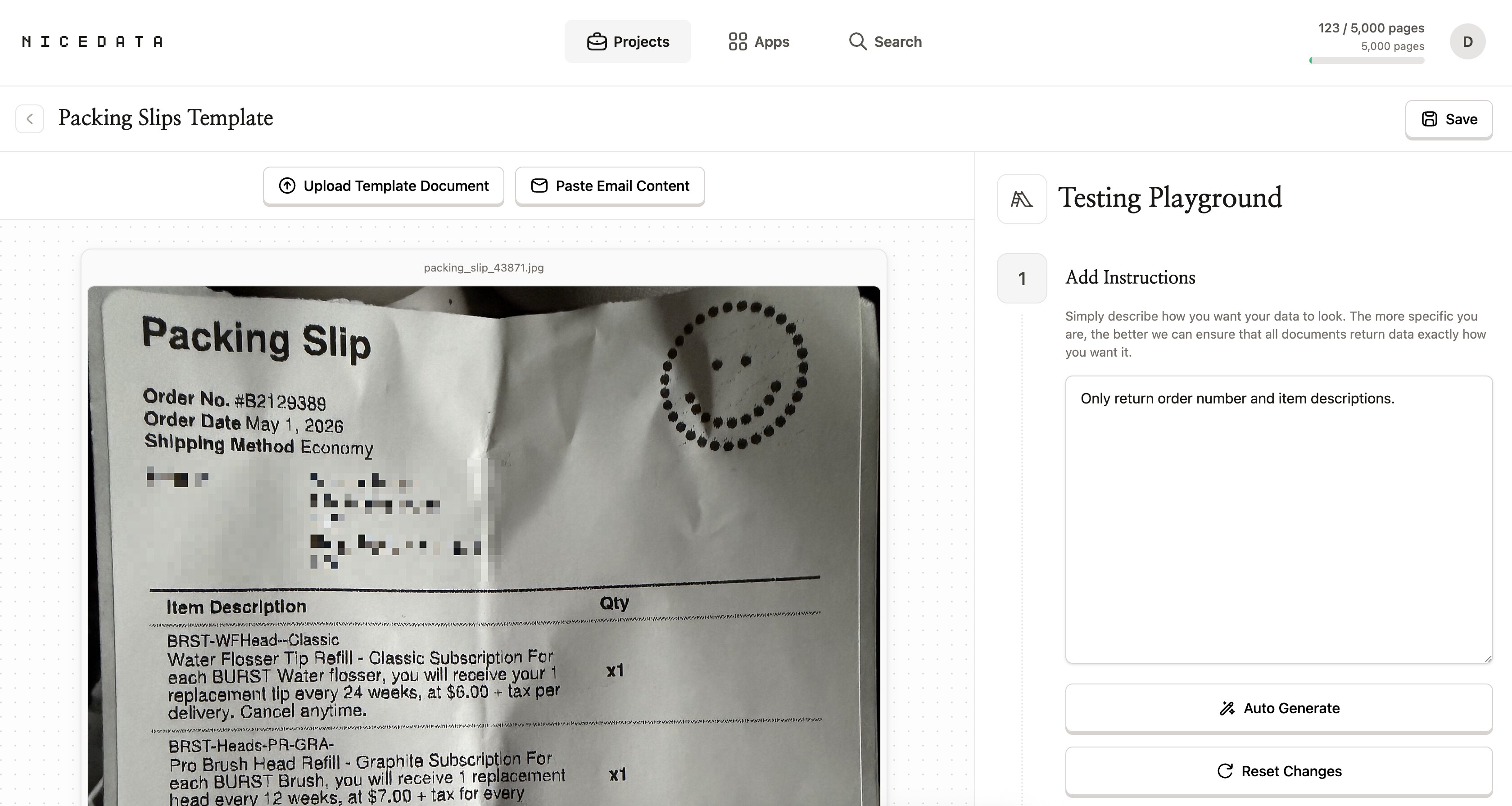
NiceData は標準で、画像の中で見つけられるすべての情報を読み取ります。注文番号と商品名だけなど、特定の項目だけが必要なら、普通の日本語で指示できます。
プロジェクトの Testing Playground を開き、指示用のテキストボックスに書きたい内容を入力します(例:「Only return order number and item descriptions.」)。それ以降、そのプロジェクトにアップロードした各画像に対して、NiceData はその指示を適用します。
ルールを書く必要はありません。項目をマッピングする必要もありません。正規表現も不要です。欲しい結果を説明するだけで、あとは NiceData が処理します。
NiceData が一番シンプルな理由
画像からテキストを抽出するとうたう多くのツールは、ユーザーに作業を強いてきます。書類の種類ごとにテンプレートを用意しないといけない。何十もの例で AI を学習させないと精度が出ない。特定のフィールドを見つけるルールを書かないといけない。API を呼ぶコードを書かないといけない。領収書 1 枚読むためだけに開発者登録をしないといけない。
NiceData はそれを全部スキップします。画像をアップロードして、NiceData が読んで、結果をダウンロードする。設定するものはなく、維持するテンプレートもなく、書くコードもありません。
ここが違いです。他のツールは大規模な技術チーム向けに作られています。NiceData は、書類と締切を抱えているすべての人のために作られています。
アップロードできるファイル形式
NiceData は、よく使われる画像と書類の形式すべてからテキストを読み取れます:
- JPG と JPEG(写真とスキャン)
- PNG(スクリーンショットや高画質画像)
- GIF
- WebP
- TIFF と TIF(スキャナーでよく使われる)
- PDF(1 ページでも複数ページでも)
データがすでに Word、Excel、CSV のいずれかになっていれば、それらもアップロードできます。NiceData はどれも同じように扱います。
抽出したテキストの書き出し方
NiceData が画像を読み終えたら、次にやりたいことに合わせて好きな形式で書き出せます。
- CSV は、データを表計算ソフトで開きたいときに最適です。各フィールドが列に、各書類が行になります。
- Excel は、ファイルを同僚と共有するのに向いています。見出しは整っていて、レイアウトもきれいで、Microsoft Excel や Google スプレッドシートでそのまま開けます。
- JSON は開発者がよく使う形式です。データを別のツール、連携、自作アプリに渡すなら、JSON が一番扱いやすいです。
- ダッシュボードからコピーは、単発の作業に一番速い方法です。NiceData で書類を開いて、必要なフィールドをコピーして、好きな場所に貼り付けるだけです。
組み合わせもできます。同じ書類をチーム用に CSV、開発者用に JSON で書き出せます。追加の手間はありません。
よくある質問
無料で試せますか?
はい。NiceData には 14 日間の無料トライアルがあり、25 ページ分の抽出が含まれます。クレジットカードは不要です。契約を決める前に、自分の書類で試せます。
コードが書けないとダメですか?
いいえ。NiceData は、コードを 1 行も書いたことがない人のために作られています。すべての作業はブラウザの中の、わかりやすい画面で完結します。ファイルをフォルダにドラッグできるなら、NiceData を使えます。
テキスト抽出の精度はどれくらいですか?
私たちの経験では、とても高いです。NiceData は最新の AI で文字を読むので、印刷された書類、スキャン、写真、ほとんどの手書きメモまで、しっかり処理できます。請求書や領収書のように文字と数字が混ざっている書類でも、どの言語でも精度を保てます。
どの言語に対応していますか?
すべての言語です。NiceData は日本語、英語、フランス語、スペイン語、ドイツ語、イタリア語、ポルトガル語、韓国語、中国語、その他何十もの言語でテキストを読み取れます。書類の言語を指定する必要はありません。自動で判別します。
複数ページの PDF も扱えますか?
はい。複数ページの PDF をアップロードすると、NiceData は各ページを読みます。各ページは月間プランの 1 ページとしてカウントされるので、10 ページの書類は 10 ページぶんを消費します。
データは安全ですか?
はい。書類は通信中も保管中も暗号化され、あなたとチームだけがアクセスできる隔離されたプロジェクトフォルダに保存されます。1 日、14 日、30 日、60 日、90 日のいずれかで自動削除する設定もできます。

Dace Willmott
Founder
NiceData aims to eliminate manual data entry from document workflows. We write about AI-powered document processing, data extraction best practices, and the tools that help teams move faster with cleaner data.