如何从 PDF 中提取数据
一份 PDF 可以包含各种各样的数据:成段的文本、一张数字表格,或是发票、表单上的几个关键字段。从 PDF 中提取数据的最佳方式取决于你需要从中获取什么,以及这些数据接下来的去向。本指南介绍主要的几种方法,然后为每一种方法提供分步操作说明。
好消息是,你不需要为不同的文档使用不同的工具。使用 NiceData,你上传 PDF,它会读取页面上的所有内容,然后你导出结果。同样的三个步骤涵盖文本、表格和完整的电子表格。
为什么从 PDF 中取出数据比看起来更难
PDF 的设计目的是在任何地方看起来都一样,而不是交出里面的数据。文件存储的是文本和线条在页面上的位置,而不是它们背后的含义。没有任何东西会说明”这个数字是合计”或”这个值属于价格列”。
这就是为什么复制粘贴常常失败。列会错位,一行折成两行的内容会被拆成两段,表头会和数据混在一起。手动重新录入既慢又容易出错。你需要的是一种能像人一样读取页面、并重建其背后数据的工具。
你要提取的是哪种数据?
先想清楚你真正需要什么,然后按照对应的指南操作:
- 一张表格(发票明细行、对账单交易记录、价格清单),其中行和列很重要。请参阅如何从 PDF 中提取表格。
- 纯文本(合同、信函、扫描的表单),你想把文字干净地提取出来。请参阅如何从 PDF 中提取文本。
- 一份可以在任何地方打开的电子表格,其中 CSV 是通用格式。请参阅如何将 PDF 转换为 CSV。
- 一个 Excel 工作簿,用于求和、筛选和数据透视。请参阅如何将 PDF 转换为 Excel。
如果你的文档是照片或截图而不是 PDF,同样的方法也适用于图像。如果你需要的是关键术语而不是每一个字,请参阅如何从文本中提取关键词。
如何使用 NiceData 从 PDF 中提取数据
无论你要提取什么,流程都是同样的三个步骤。
第 1 步:上传你的 PDF
登录 NiceData,把你的 PDF 拖到上传区域。可以拖入单个文件,也可以一次拖入多个。单页和多页 PDF 都可以,扫描的 PDF 和页面照片也都没问题。更喜欢用邮箱?每个项目都有自己的电子邮件地址,所以你可以把 PDF 作为附件发送邮件,直接传进来。
第 2 步:让 NiceData 读取页面
上传一完成,NiceData 就会读取文档。它使用 AI 识别页面上的文本、表格、日期和金额,并将它们整理成干净的结构化数据。你不需要标注任何内容,也不需要告诉它字段在哪里。它会自己分辨清楚,即使是它从未见过的版式也一样。
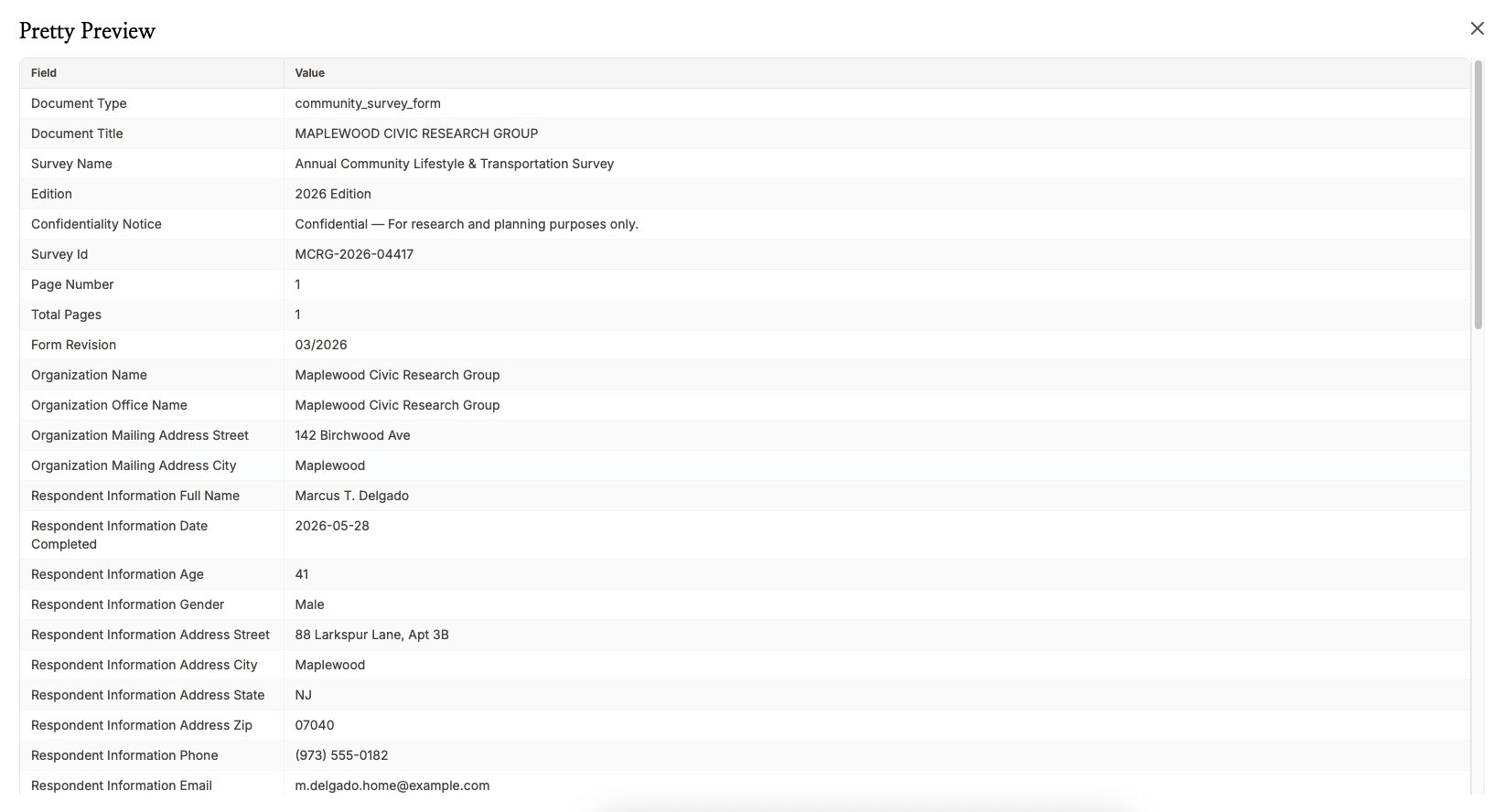
第 3 步:导出你的数据
提取完成后,点击下载按钮并选择你的格式。CSV 和 Excel 可以直接在电子表格中打开,JSON 可供另一个系统使用,或者你也可以从仪表盘复制你需要的字段。
选择合适的导出格式
你选择的格式取决于数据接下来的去向:
- CSV 是通用之选。它可以在 Excel、Google Sheets 以及几乎所有商业工具中打开。
- Excel 最适合在你想要带样式的表头、公式和数据透视表时使用,或者当你要和同事共享文件时使用。
- JSON 是开发人员偏爱的格式,适用于数据要输送到另一个工具、集成或自定义应用的场景。
- 从仪表盘复制对于一次性操作最快捷,当你只需要把几个字段粘贴到某处时很方便。
你可以自由组合。把同一份 PDF 导出为 CSV 给财务团队,再导出为 JSON 给开发人员,无需任何额外步骤。如果数据最终要落进团队每天手动录入的电子表格工具里,请参阅我们对最佳数据录入软件的对比。
为什么 NiceData 是从 PDF 中提取数据最简单的方式
大多数承诺能从 PDF 中提取数据的工具都要求你先做设置。你要为每种文档类型绘制一个可视化模板,把每个字段映射到页面上的某个区域。你要用几十个带标注的样本训练模型。你要为棘手的部分编写规则。有些工具甚至在提取出第一个字段之前,就把整个工作交给开发人员和一个 API 账户。
NiceData 跳过了所有这些。你上传 PDF,它读取页面,你下载数据。如果你想微调提取的内容,你可以创建一个模板,用通俗的语言描述你想要什么,然后在一个样本上测试它。无需字段映射,无需模型训练,无需代码。
这就是区别所在。其他工具是为大型技术团队打造的。NiceData 是为任何有 PDF 和截止日期的人打造的。在价格页面选择一个方案,或者先用免费试用,在你自己的文档上运行它。
你可以上传哪些文件类型
PDF 是本指南的主角格式,但 NiceData 几乎可以读取任何类型的文档:
- PDF(单页或多页,数字版或扫描版)
- JPG 和 JPEG(照片和扫描件)
- PNG(截图和高质量图像)
- TIFF 和 TIF(扫描仪常用)
- GIF 和 WebP
- Word 文档(DOC 和 DOCX)
- Excel 文件(XLS 和 XLSX)
- CSV 和纯文本文件
你可以把它们全部放进同一个项目,也可以用邮件发送进来。NiceData 都会以同样的方式处理它们。
常见问题
从 PDF 中提取数据是什么意思?
它的意思是把锁在 PDF 里的内容,也就是你在屏幕上看到的文本、表格、日期和金额,转换成可以编辑、排序和重复使用的结构化数据。PDF 存储的是一页固定的图像,所以必须先把数据读取出来,你才能在电子表格或其他工具中使用它。
可以免费试用吗?
可以。NiceData 提供 14 天免费试用,包含 25 页的提取额度,而且无需信用卡。这足以让你在自己的 PDF 上运行它,并在决定之前看到结果。
我需要任何技术技能吗?
完全不需要。NiceData 完全在你的浏览器中运行,专为从未写过代码的人打造。如果你会把文件拖进文件夹,你就会从 PDF 中提取数据。
我应该选择哪种导出格式?
如果需要可以在任何地方打开的纯行列数据,就用 CSV;如果想要带样式的表头和公式,就用 Excel;如果开发人员或其他系统需要这些数据,就用 JSON。你可以把同一份文档导出为多种格式。
它适用于扫描的 PDF 和照片吗?
可以。NiceData 读取扫描的 PDF、页面照片和略有倾斜的图像,方式和读取干净的数字导出文件一样,所以你不需要先用别的工具处理它们。
我的数据安全吗?
安全。文档在传输和存储过程中均经过加密,并保存在只有你和你的团队才能打开的独立项目文件夹中。你还可以设置它们在 1、14、30、60 或 90 天后自动删除。
相关指南

Dace Willmott
Founder
NiceData aims to eliminate manual data entry from document workflows. We write about AI-powered document processing, data extraction best practices, and the tools that help teams move faster with cleaner data.