Cómo extraer datos de un PDF
Un PDF puede contener todo tipo de datos: párrafos de texto, una tabla de cifras o unos pocos campos clave en una factura o un formulario. La mejor forma de extraer datos de un PDF depende de qué necesitas obtener y de adónde van esos datos después. Esta guía explica los enfoques principales y luego te lleva a un paso a paso para cada uno.
La buena noticia es que no necesitas herramientas distintas para documentos distintos. Con NiceData subes el PDF, este lee lo que haya en la página y tú exportas el resultado. Los mismos tres pasos sirven para texto, tablas y hojas de cálculo completas.
Por qué sacar datos de un PDF es más difícil de lo que parece
Un PDF se diseñó para verse igual en todas partes, no para entregar los datos que contiene. El archivo guarda la posición del texto y las líneas en la página, no el significado que hay detrás. No hay nada que diga “este número es un total” o “este valor pertenece a la columna de precio”.
Por eso copiar y pegar falla tan a menudo. Las columnas se descuadran, una fila que ocupaba dos líneas se parte en dos y los encabezados se mezclan con los datos. Volver a teclearlo a mano es lento e introduce errores. Lo que quieres es una herramienta que lea la página como lo haría una persona y reconstruya los datos que hay detrás.
¿Qué tipo de datos quieres extraer?
Empieza por la pregunta de qué necesitas en realidad y luego sigue la guía que corresponda:
- Una tabla (líneas de una factura, transacciones de un extracto, una lista de precios) donde las filas y columnas importan. Consulta cómo extraer tablas de un PDF.
- Texto sin formato (un contrato, una carta, un formulario escaneado) donde quieres las palabras limpias. Consulta cómo extraer texto de un PDF.
- Una hoja de cálculo que se abre en cualquier sitio, donde CSV es el formato universal. Consulta cómo convertir un PDF a CSV.
- Un libro de Excel para totales, filtros y tablas dinámicas. Consulta cómo convertir un PDF a Excel.
Si tu documento es una foto o una captura de pantalla en lugar de un PDF, el mismo enfoque también funciona con imágenes. Y cuando necesitas los términos clave en lugar de cada palabra, consulta cómo extraer palabras clave de un texto.
Cómo extraer datos de un PDF con NiceData
Sea lo que sea lo que quieras obtener, el proceso son los mismos tres pasos.
Paso 1: Sube tu PDF
Inicia sesión en NiceData y arrastra tu PDF al área de subida. Suelta un solo archivo o muchos a la vez. Funcionan los PDF de una página y los de varias páginas, y también los PDF escaneados y las fotos de páginas. ¿Prefieres tu bandeja de entrada? Cada proyecto tiene su propia dirección de correo, así que puedes adjuntar un PDF a un correo y enviarlo directamente.
Paso 2: Deja que NiceData lea la página
En cuanto termina la subida, NiceData lee el documento. Usa IA para reconocer el texto, las tablas, las fechas y los importes de la página y organizarlos en datos limpios y estructurados. No marcas nada ni le indicas dónde están los campos. Lo averigua por sí solo, incluso con un diseño que nunca ha visto antes.
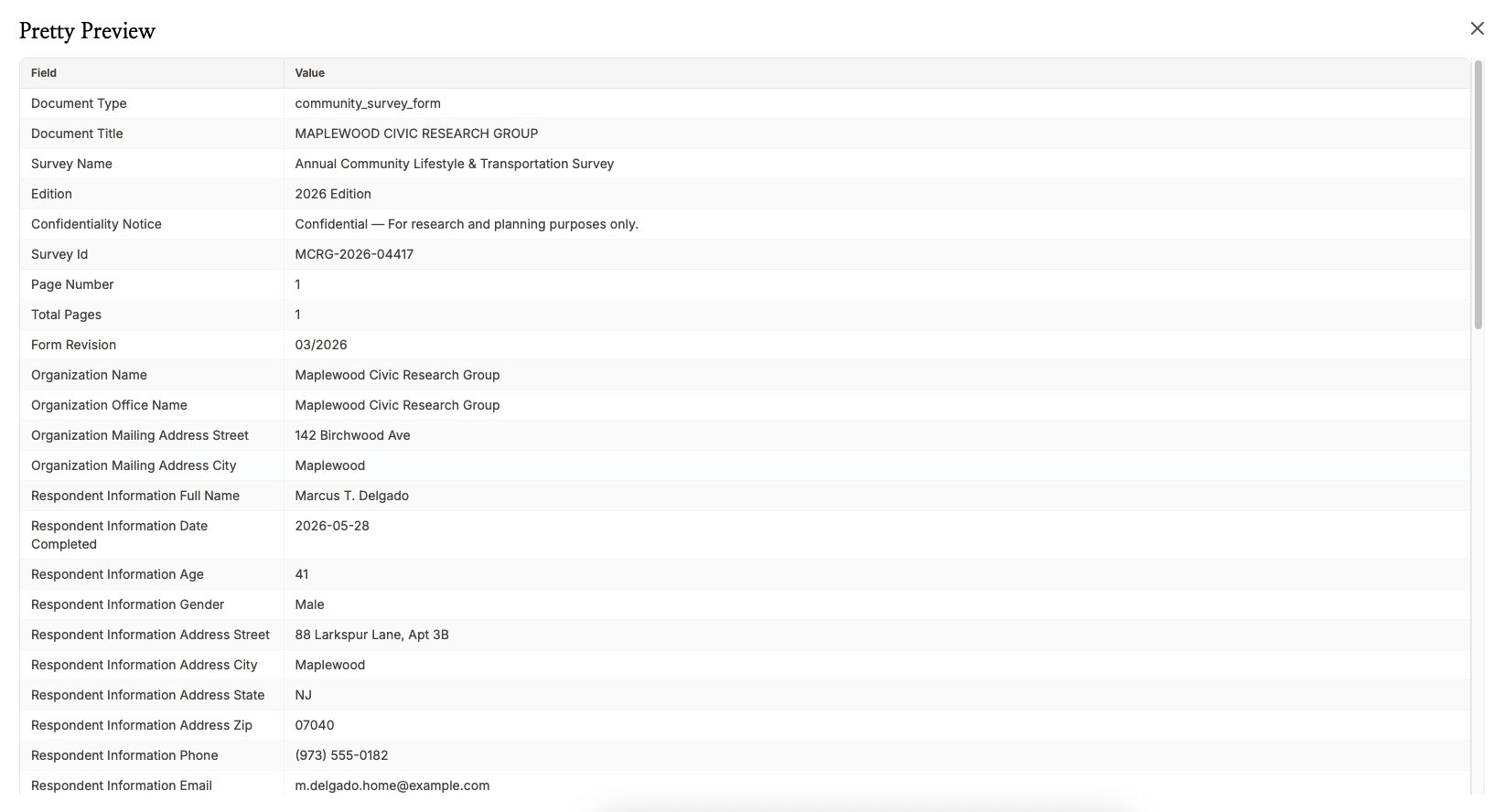
Paso 3: Exporta tus datos
Una vez terminada la extracción, haz clic en el botón de Descargar y elige tu formato. CSV y Excel se abren directamente en una hoja de cálculo, JSON está listo para otro sistema, o puedes copiar los campos que necesites desde el panel.
Cómo elegir el formato de exportación adecuado
El formato que elijas depende de adónde van los datos después:
- CSV es la opción universal. Se abre en Excel, Google Sheets y casi cualquier herramienta de negocio que se haya creado.
- Excel es lo mejor cuando quieres encabezados con estilo, fórmulas y tablas dinámicas, o cuando compartes el archivo con colegas.
- JSON es el formato que prefieren los desarrolladores cuando los datos alimentan otra herramienta, una integración o una aplicación a medida.
- Copiar desde el panel es lo más rápido para un caso puntual, cuando solo necesitas pegar unos pocos campos en algún sitio.
Puedes combinarlos. Exporta el mismo PDF como CSV para tu equipo de finanzas y como JSON para tu desarrollador, sin pasos adicionales. Y si el destino final de los datos es una herramienta de hoja de cálculo en la que tu equipo escribe cada día, consulta nuestra comparativa del mejor software de entrada de datos.
Por qué NiceData es la forma más sencilla de extraer datos de un PDF
La mayoría de las herramientas que prometen extraer datos de un PDF te obligan a configurarlas primero. Dibujas una plantilla visual sobre cada tipo de documento, asignando cada campo a una región de la página. Entrenas un modelo con decenas de ejemplos etiquetados. Escribes reglas para las partes complicadas. Algunas dejan todo el trabajo en manos de un desarrollador y una cuenta de API antes de que salga un solo campo.
NiceData se salta todo eso. Subes un PDF, este lee la página, tú descargas los datos. Si quieres afinar lo que se extrae, creas una plantilla y describes lo que quieres en lenguaje sencillo, y luego la pruebas con una muestra. Sin asignación de campos, sin entrenar modelos, sin código.
Esa es la diferencia. Otras herramientas están hechas para grandes equipos técnicos. NiceData está hecho para cualquiera que tenga un PDF y una fecha de entrega. Elige un plan en la página de precios o empieza con la prueba gratuita y úsala con tus propios documentos.
Qué tipos de archivo puedes subir
PDF es el formato protagonista de esta guía, pero NiceData lee casi cualquier tipo de documento:
- PDF (una página o varias, digital o escaneado)
- JPG y JPEG (fotos y escaneos)
- PNG (capturas de pantalla e imágenes de alta calidad)
- TIFF y TIF (a menudo usados por los escáneres)
- GIF y WebP
- Documentos de Word (DOC y DOCX)
- Archivos de Excel (XLS y XLSX)
- CSV y archivos de texto sin formato
Suéltalos todos en el mismo proyecto si quieres, o envíalos por correo. NiceData los trata de la misma forma.
Preguntas frecuentes
¿Qué significa extraer datos de un PDF?
Significa convertir el contenido atrapado dentro de un PDF, es decir, el texto, las tablas, las fechas y los importes que ves en pantalla, en datos estructurados que puedes editar, ordenar y reutilizar. Un PDF guarda una imagen fija de la página, así que hay que volver a leer los datos antes de poder usarlos en una hoja de cálculo u otra herramienta.
¿Es gratis probarlo?
Sí. NiceData incluye una prueba gratuita de 14 días con 25 páginas de extracción, y no necesitas tarjeta de crédito. Es suficiente para usarlo con tus propios PDF y ver los resultados antes de decidir.
¿Necesito conocimientos técnicos?
Ninguno. NiceData funciona por completo en tu navegador y está pensado para personas que nunca han escrito código. Si sabes arrastrar un archivo a una carpeta, puedes extraer datos de un PDF.
¿Qué formato de exportación debería elegir?
Usa CSV para filas y columnas simples que se abren en cualquier sitio, Excel cuando quieras encabezados con estilo y fórmulas, y JSON cuando un desarrollador u otro sistema necesite los datos. Puedes exportar el mismo documento en más de un formato.
¿Funciona con PDF escaneados y fotos?
Sí. NiceData lee PDF escaneados, fotos de páginas e imágenes ligeramente torcidas igual que lee una exportación digital limpia, así que no necesitas pasarlos por nada más antes.
¿Están seguros mis datos?
Sí. Los documentos se cifran en tránsito y en reposo, y se guardan en carpetas de proyecto aisladas que solo tú y tu equipo podéis abrir. También puedes configurarlos para que se borren automáticamente después de 1, 14, 30, 60 o 90 días.
Guías relacionadas
Extraer texto de una imagen
Extrae texto de cualquier imagen en segundos con NiceData. Sube una foto, captura o escaneo y exporta los datos como JSON, CSV o Excel. Sin código.
Extraer palabras clave de un texto
Extrae palabras clave de un texto en segundos con NiceData. Sube un archivo, saca los términos clave y exporta a CSV, Excel o JSON. Pruébalo gratis.
Automatización de la entrada de datos
La automatización de la entrada de datos convierte facturas, recibos y formularios en datos estructurados en segundos. Sin código ni tecleo. Pruébalo gratis.

Dace Willmott
Founder
NiceData aims to eliminate manual data entry from document workflows. We write about AI-powered document processing, data extraction best practices, and the tools that help teams move faster with cleaner data.